 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability of the Monge Map in Semi-Dual Optimal Transport
May 07, 2026This paper shows that the semi-dual formulation of the optimal transport problem has a degenerate saddle-point structure, and that its numerical solution is equivalent to solving a constrained optimization problem. We derive necessary and sufficient conditions for the convergence of Monge maps without requiring optimality of the dual potential. This analysis helps explain why, in practice, numerical algorithms often require more iterations to update the transport map than the potential.
Discrete optimal transport is a strong audio adversarial attack
Sep 18, 2025In this paper, we show that discrete optimal transport (DOT) is an effective black-box adversarial attack against modern audio anti-spoofing countermeasures (CMs). Our attack operates as a post-processing, distribution-alignment step: frame-level WavLM embeddings of generated speech are aligned to an unpaired bona fide pool via entropic OT and a top-$k$ barycentric projection, then decoded with a neural vocoder. Evaluated on ASVspoof2019 and ASVspoof5 with AASIST baselines, DOT yields consistently high equal error rate (EER) across datasets and remains competitive after CM fine-tuning, outperforming several conventional attacks in cross-dataset transfer. Ablation analysis highlights the practical impact of vocoder overlap. Results indicate that distribution-level alignment is a powerful and stable attack surface for deployed CMs.
Discrete Optimal Transport and Voice Conversion
May 07, 2025In this work, we address the voice conversion (VC) task using a vector-based interface. To align audio embeddings between speakers, we employ discrete optimal transport mapping. Our evaluation results demonstrate the high quality and effectiveness of this method. Additionally, we show that applying discrete optimal transport as a post-processing step in audio generation can lead to the incorrect classification of synthetic audio as real.
Music Source Separation with Generative Flow
Apr 26, 2022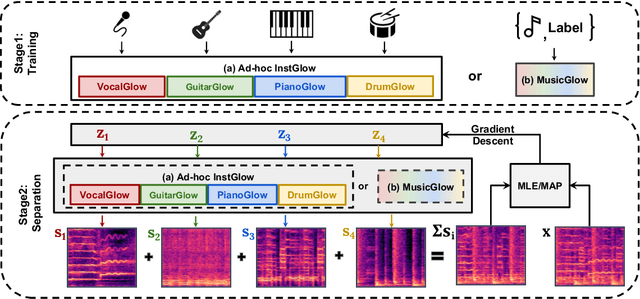
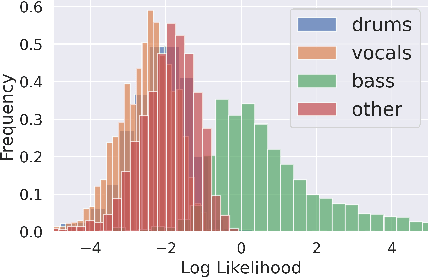
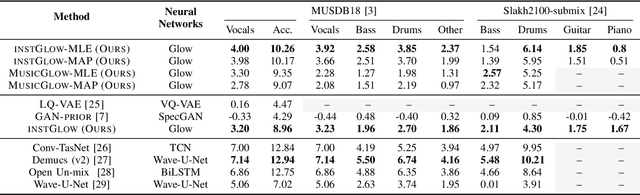
Full supervision models for source separation are trained on mixture-source parallel data and have achieved superior performance in recent years. However, large-scale and naturally mixed parallel training data are difficult to obtain for music, and such models are difficult to adapt to mixtures with new sources. Source-only supervision models, in contrast, only require clean sources for training; They learn source models and then apply these models to separate the mixture.