 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Token Fusion for Vision Transformers
Paper and Code
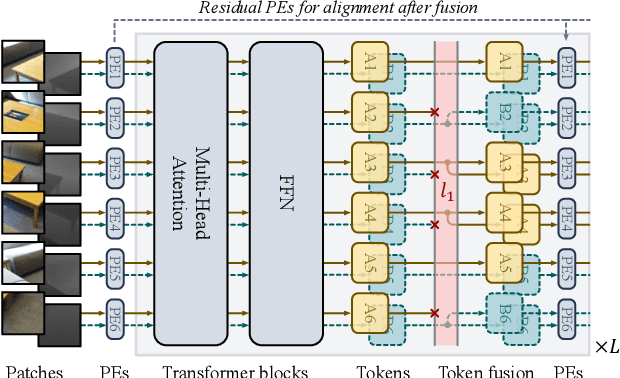
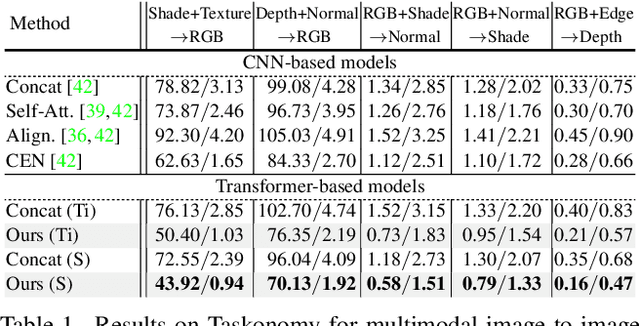
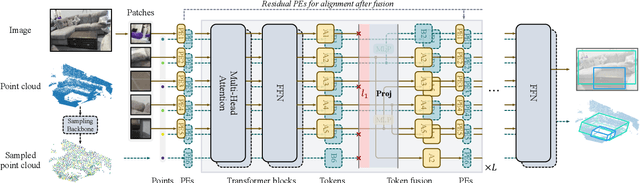
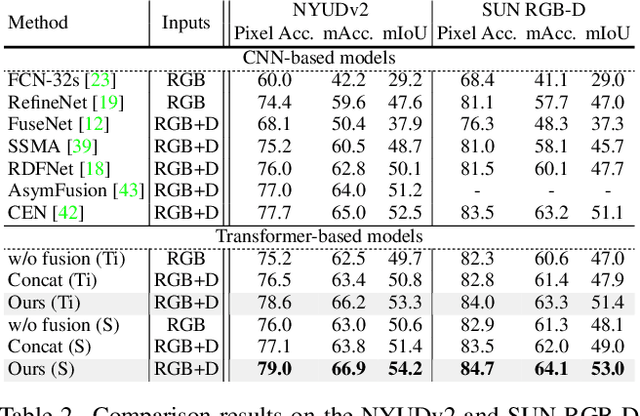
Many adaptations of transformers have emerged to address the single-modal vision tasks, where self-attention modules are stacked to handle input sources like images. Intuitively, feeding multiple modalities of data to vision transformers could improve the performance, yet the inner-modal attentive weights may also be diluted, which could thus undermine the final performance. In this paper, we propose a multimodal token fusion method (TokenFusion), tailored for transformer-based vision tasks. To effectively fuse multiple modalities, TokenFusion dynamically detects uninformative tokens and substitutes these tokens with projected and aggregated inter-modal features. Residual positional alignment is also adopted to enable explicit utilization of the inter-modal alignments after fusion. The design of TokenFusion allows the transformer to learn correlations among multimodal features, while the single-modal transformer architecture remains largely intact. Extensive experiments are conducted on a variety of homogeneous and heterogeneous modalities and demonstrate that TokenFusion surpasses state-of-the-art methods in three typical vision tasks: multimodal image-to-image translation, RGB-depth semantic segmentation, and 3D object detection with point cloud and images.