 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHSCNet: A Multimodal Hierarchical Shot-aware Convolutional Network for Video Summarization
Paper and Code
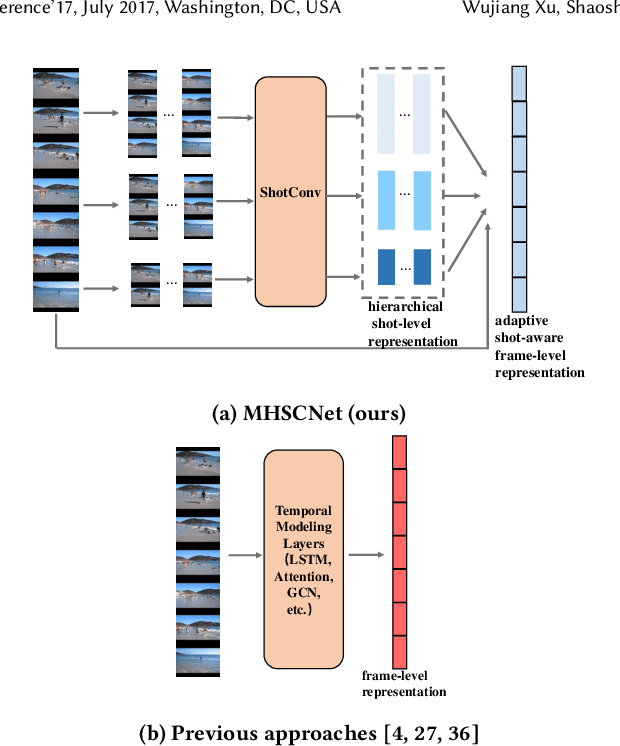
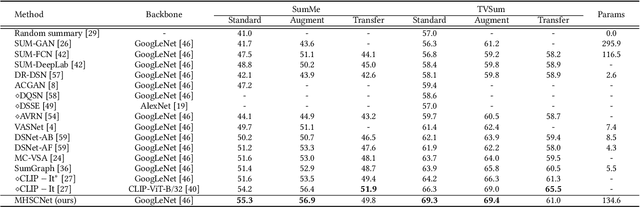
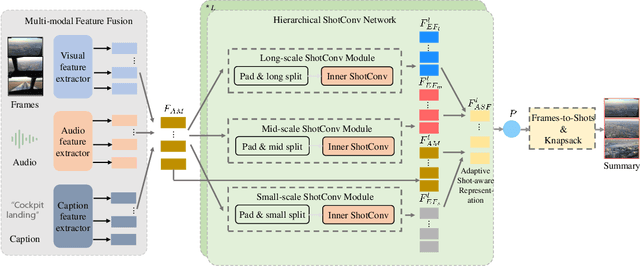
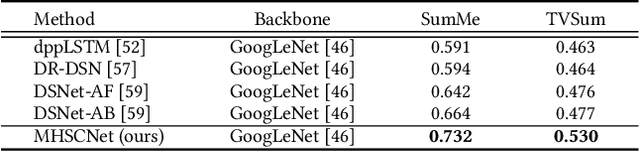
Video summarization intends to produce a concise video summary by effectively capturing and combining the most informative parts of the whole content. Existing approaches for video summarization regard the task as a frame-wise keyframe selection problem and generally construct the frame-wise representation by combining the long-range temporal dependency with the unimodal or bimodal information. However, the optimal video summaries need to reflect the most valuable keyframe with its own information, and one with semantic power of the whole content. Thus, it is critical to construct a more powerful and robust frame-wise representation and predict the frame-level importance score in a fair and comprehensive manner. To tackle the above issues, we propose a multimodal hierarchical shot-aware convolutional network, denoted as MHSCNet, to enhance the frame-wise representation via combining the comprehensive available multimodal information. Specifically, we design a hierarchical ShotConv network to incorporate the adaptive shot-aware frame-level representation by considering the short-range and long-range temporal dependency. Based on the learned shot-aware representations, MHSCNet can predict the frame-level importance score in the local and global view of the video. Extensive experiments on two standard video summarization datasets demonstrate that our proposed method consistently outperforms state-of-the-art baselines. Source code will be made publicly available.