 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive 3D Shape Generation via Canonical Mapping
Paper and Code
Apr 05, 2022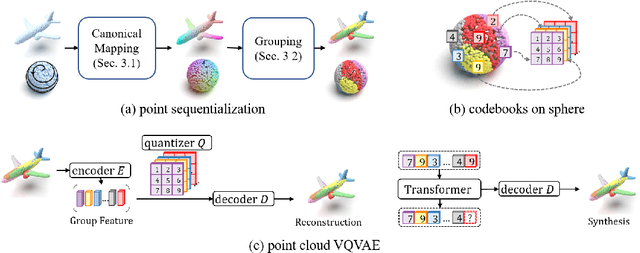
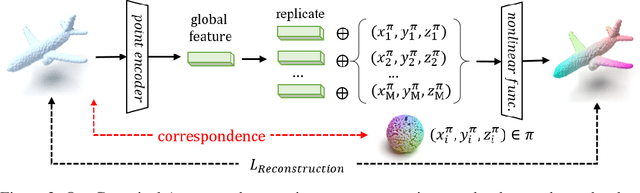
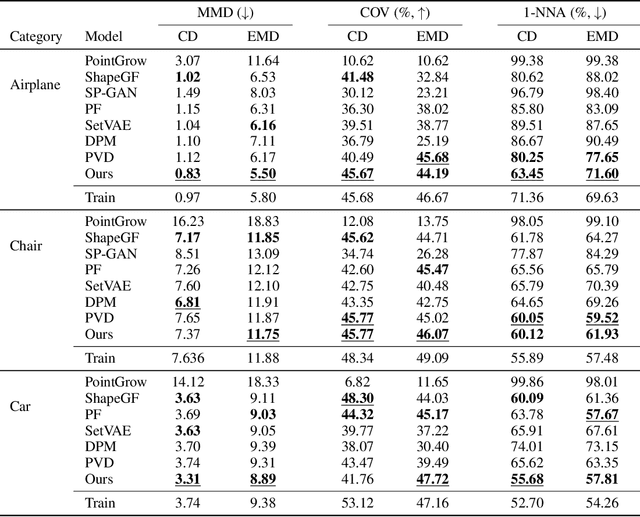
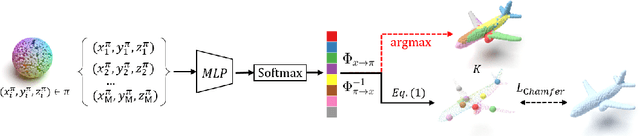
With the capacity of modeling long-range dependencies in sequential data, transformers have shown remarkable performances in a variety of generative tasks such as image, audio, and text generation. Yet, taming them in generating less structured and voluminous data formats such as high-resolution point clouds have seldom been explored due to ambiguous sequentialization processes and infeasible computation burden. In this paper, we aim to further exploit the power of transformers and employ them for the task of 3D point cloud generation. The key idea is to decompose point clouds of one category into semantically aligned sequences of shape compositions, via a learned canonical space. These shape compositions can then be quantized and used to learn a context-rich composition codebook for point cloud generation. Experimental results on point cloud reconstruction and unconditional generation show that our model performs favorably against state-of-the-art approaches. Furthermore, our model can be easily extended to multi-modal shape completion as an application for conditional shape generation.