 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
Paper and Code
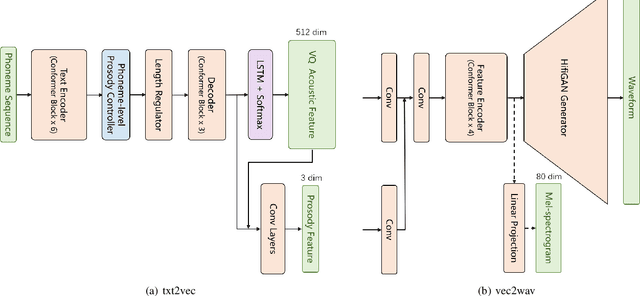
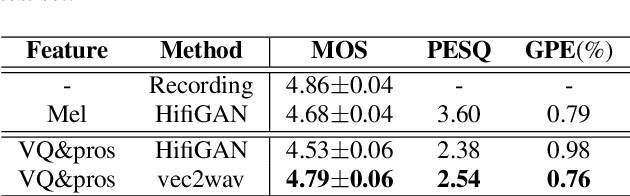
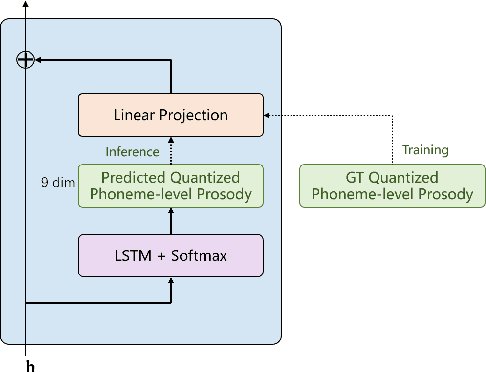
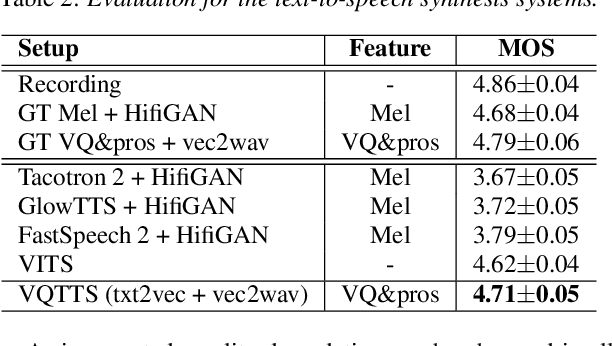
The mainstream neural text-to-speech(TTS) pipeline is a cascade system, including an acoustic model(AM) that predicts acoustic feature from the input transcript and a vocoder that generates waveform according to the given acoustic feature. However, the acoustic feature in current TTS systems is typically mel-spectrogram, which is highly correlated along both time and frequency axes in a complicated way, leading to a great difficulty for the AM to predict. Although high-fidelity audio can be generated by recent neural vocoders from ground-truth(GT) mel-spectrogram, the gap between the GT and the predicted mel-spectrogram from AM degrades the performance of the entire TTS system. In this work, we propose VQTTS, consisting of an AM txt2vec and a vocoder vec2wav, which uses self-supervised vector-quantized(VQ) acoustic feature rather than mel-spectrogram. We redesign both the AM and the vocoder accordingly. In particular, txt2vec basically becomes a classification model instead of a traditional regression model while vec2wav uses an additional feature encoder before HifiGAN generator for smoothing the discontinuous quantized feature. Our experiments show that vec2wav achieves better reconstruction performance than HifiGAN when using self-supervised VQ acoustic feature. Moreover, our entire TTS system VQTTS achieves state-of-the-art performance in terms of naturalness among all current publicly available TTS systems.