 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Agnostic Multitask Fine-tuning for Few-shot Vision-Language Transfer Learning
Paper and Code
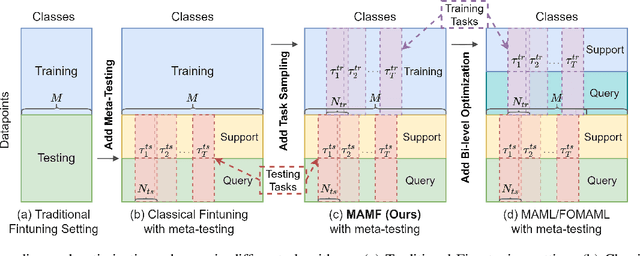
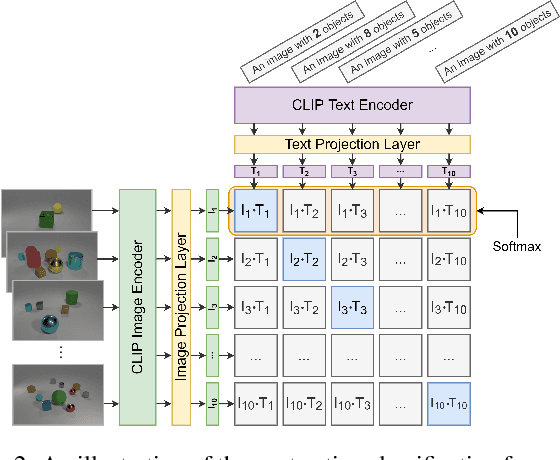
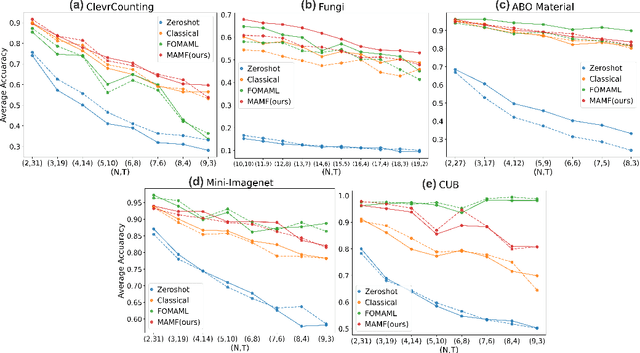
Despite achieving state-of-the-art zero-shot performance, existing vision-language models, e.g., CLIP, still fall short of domain-specific classification tasks, e.g., Fungi Classification. In the context of few-shot transfer learning, traditional fine-tuning fails to prevent highly expressive model from exploiting spurious correlations in the training data. On the other hand, although model-agnostic meta-learning (MAML) presents as a natural alternative for transfer learning, the expensive computation due to implicit second-order optimization limits its use in large-scale models and datasets. In this work we aim to further improve the generalization of existing vision-language models on unseen tasks via a simple yet efficient fine-tuning strategy based on uniform task sampling. We term our method as Model-Agnostic Multitask Fine-tuning (MAMF). Compared with MAML, MAMF discards the bi-level optimization and uses only first-order gradients, which makes it easily scalable and computationally efficient. Due to the uniform task sampling procedure, MAMF consistently outperforms the classical fine-tuning method for few-shot transfer learning on five benchmark datasets. Empirically, we further discover that the effectiveness of first-order MAML is highly dependent on the zero-shot performance of the pretrained model, and our simple algorithm can outperform first-order MAML on more challenging datasets with low zero-shot performance.