 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Vision-Language Pre-Trained Models
Paper and Code
Feb 18, 2022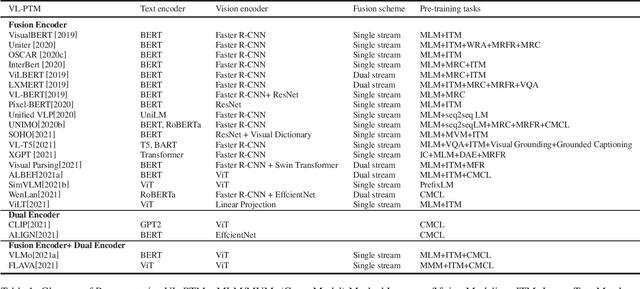
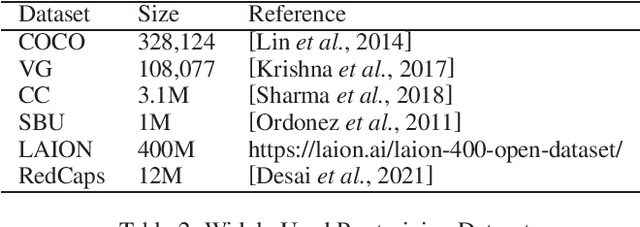

As Transformer evolved, pre-trained models have advanced at a breakneck pace in recent years. They have dominated the mainstream techniques in natural language processing (NLP) and computer vision (CV). How to adapt pre-training to the field of Vision-and-Language (V-L) learning and improve the performance on downstream tasks becomes a focus of multimodal learning. In this paper, we review the recent progress in Vision-Language Pre-Trained Models (VL-PTMs). As the core content, we first briefly introduce several ways to encode raw images and texts to single-modal embeddings before pre-training. Then, we dive into the mainstream architectures of VL-PTMs in modeling the interaction between text and image representations. We further present widely-used pre-training tasks, after which we introduce some common downstream tasks. We finally conclude this paper and present some promising research directions. Our survey aims to provide multimodal researchers a synthesis and pointer to related research.