 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocumenting Geographically and Contextually Diverse Data Sources: The BigScience Catalogue of Language Data and Resources
Paper and Code
Jan 25, 2022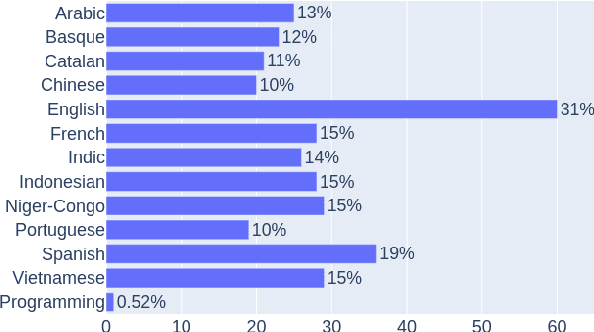
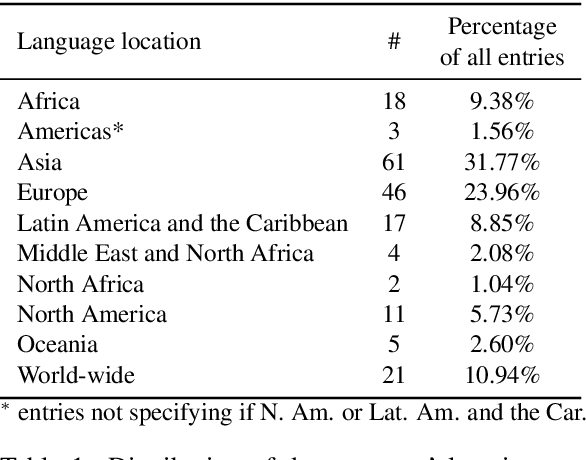
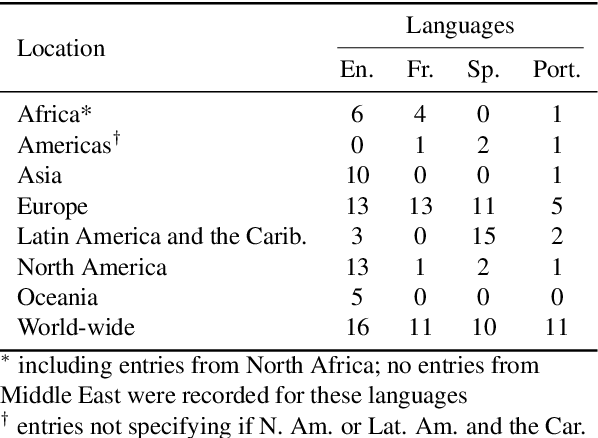
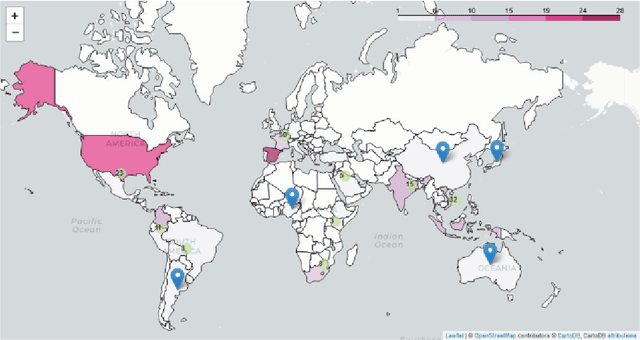
In recent years, large-scale data collection efforts have prioritized the amount of data collected in order to improve the modeling capabilities of large language models. This prioritization, however, has resulted in concerns with respect to the rights of data subjects represented in data collections, particularly when considering the difficulty in interrogating these collections due to insufficient documentation and tools for analysis. Mindful of these pitfalls, we present our methodology for a documentation-first, human-centered data collection project as part of the BigScience initiative. We identified a geographically diverse set of target language groups (Arabic, Basque, Chinese, Catalan, English, French, Indic languages, Indonesian, Niger-Congo languages, Portuguese, Spanish, and Vietnamese, as well as programming languages) for which to collect metadata on potential data sources. To structure this effort, we developed our online catalogue as a supporting tool for gathering metadata through organized public hackathons. We present our development process; analyses of the resulting resource metadata, including distributions over languages, regions, and resource types; and our lessons learned in this endeavor.