 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Weighted Layer Representation Based View Synthesis Distortion Estimation for 3-D Video Coding
Paper and Code

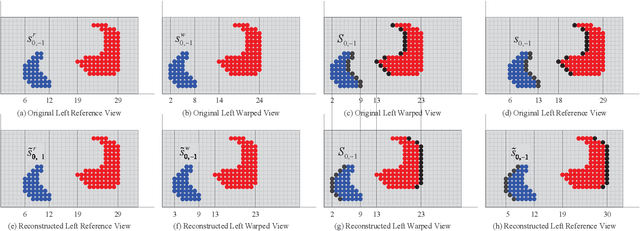
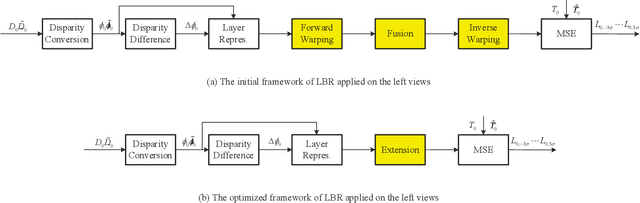
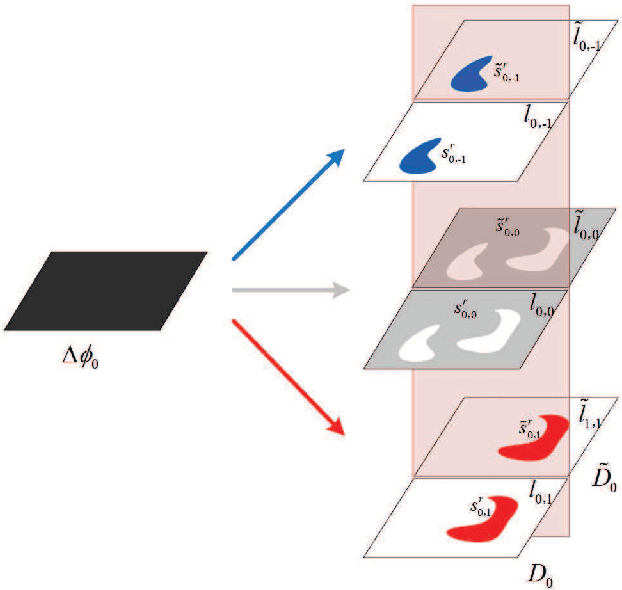
Recently, various view synthesis distortion estimation models have been studied to better serve for 3-D video coding. However, they can hardly model the relationship quantitatively among different levels of depth changes, texture degeneration, and the view synthesis distortion (VSD), which is crucial for rate-distortion optimization and rate allocation. In this paper, an auto-weighted layer representation based view synthesis distortion estimation model is developed. Firstly, the sub-VSD (S-VSD) is defined according to the level of depth changes and their associated texture degeneration. After that, a set of theoretical derivations demonstrate that the VSD can be approximately decomposed into the S-VSDs multiplied by their associated weights. To obtain the S-VSDs, a layer-based representation of S-VSD is developed, where all the pixels with the same level of depth changes are represented with a layer to enable efficient S-VSD calculation at the layer level. Meanwhile, a nonlinear mapping function is learnt to accurately represent the relationship between the VSD and S-VSDs, automatically providing weights for S-VSDs during the VSD estimation. To learn such function, a dataset of VSD and its associated S-VSDs are built. Experimental results show that the VSD can be accurately estimated with the weights learnt by the nonlinear mapping function once its associated S-VSDs are available. The proposed method outperforms the relevant state-of-the-art methods in both accuracy and efficiency. The dataset and source code of the proposed method will be available at https://github.com/jianjin008/.