 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2P-Loc: Point to Point Tiny Person Localization
Paper and Code
Jan 05, 2022

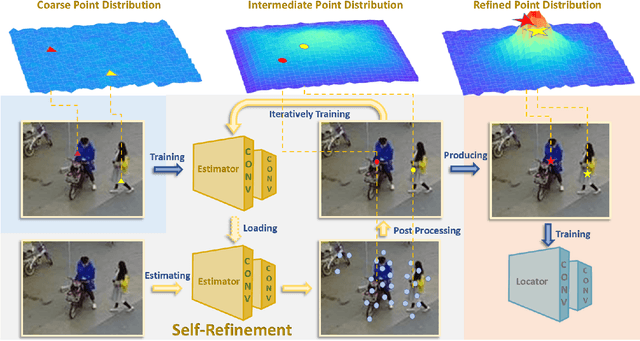

Bounding-box annotation form has been the most frequently used method for visual object localization tasks. However, bounding-box annotation relies on a large amount of precisely annotating bounding boxes, and it is expensive and laborious. It is impossible to be employed in practical scenarios and even redundant for some applications (such as tiny person localization) that the size would not matter. Therefore, we propose a novel point-based framework for the person localization task by annotating each person as a coarse point (CoarsePoint) instead of an accurate bounding box that can be any point within the object extent. Then, the network predicts the person's location as a 2D coordinate in the image. Although this greatly simplifies the data annotation pipeline, the CoarsePoint annotation inevitably decreases label reliability (label uncertainty) and causes network confusion during training. As a result, we propose a point self-refinement approach that iteratively updates point annotations in a self-paced way. The proposed refinement system alleviates the label uncertainty and progressively improves localization performance. Experimental results show that our approach has achieved comparable object localization performance while saving up to 80$\%$ of annotation cost.