 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuronFair: Interpretable White-Box Fairness Testing through Biased Neuron Identification
Paper and Code
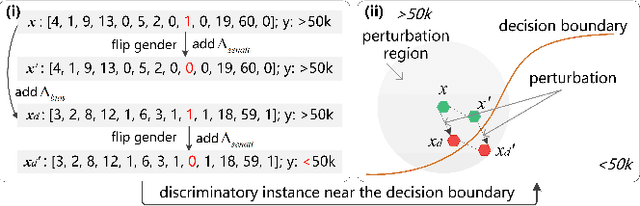
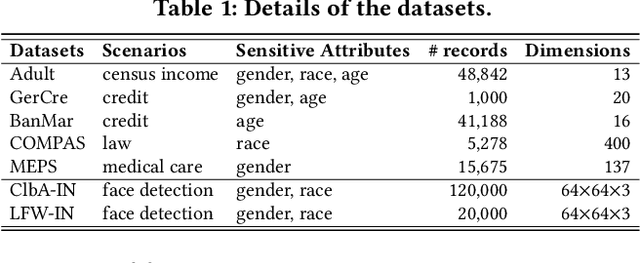
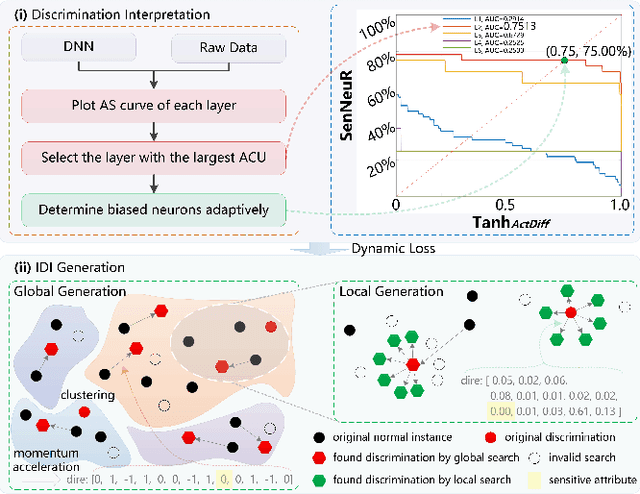
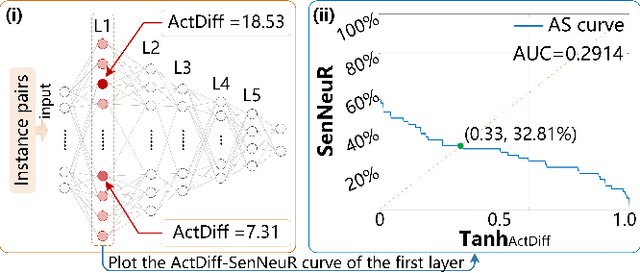
Deep neural networks (DNNs) have demonstrated their outperformance in various domains. However, it raises a social concern whether DNNs can produce reliable and fair decisions especially when they are applied to sensitive domains involving valuable resource allocation, such as education, loan, and employment. It is crucial to conduct fairness testing before DNNs are reliably deployed to such sensitive domains, i.e., generating as many instances as possible to uncover fairness violations. However, the existing testing methods are still limited from three aspects: interpretability, performance, and generalizability. To overcome the challenges, we propose NeuronFair, a new DNN fairness testing framework that differs from previous work in several key aspects: (1) interpretable - it quantitatively interprets DNNs' fairness violations for the biased decision; (2) effective - it uses the interpretation results to guide the generation of more diverse instances in less time; (3) generic - it can handle both structured and unstructured data. Extensive evaluations across 7 datasets and the corresponding DNNs demonstrate NeuronFair's superior performance. For instance, on structured datasets, it generates much more instances (~x5.84) and saves more time (with an average speedup of 534.56%) compared with the state-of-the-art methods. Besides, the instances of NeuronFair can also be leveraged to improve the fairness of the biased DNNs, which helps build more fair and trustworthy deep learning systems.