 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetween words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP
Paper and Code
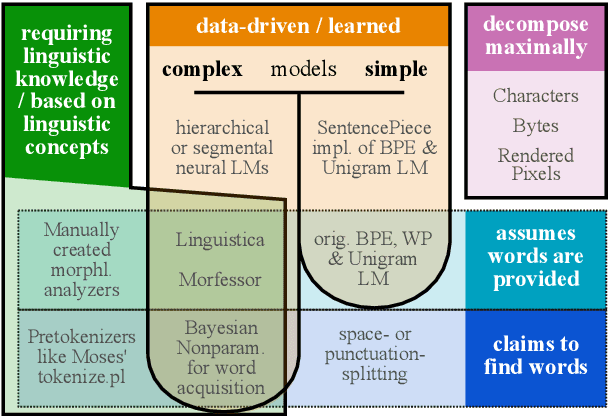
What are the units of text that we want to model? From bytes to multi-word expressions, text can be analyzed and generated at many granularities. Until recently, most natural language processing (NLP) models operated over words, treating those as discrete and atomic tokens, but starting with byte-pair encoding (BPE), subword-based approaches have become dominant in many areas, enabling small vocabularies while still allowing for fast inference. Is the end of the road character-level model or byte-level processing? In this survey, we connect several lines of work from the pre-neural and neural era, by showing how hybrid approaches of words and characters as well as subword-based approaches based on learned segmentation have been proposed and evaluated. We conclude that there is and likely will never be a silver bullet singular solution for all applications and that thinking seriously about tokenization remains important for many applications.