 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAC-GAN: Structure-Aware Image-to-Image Composition for Self-Driving
Paper and Code

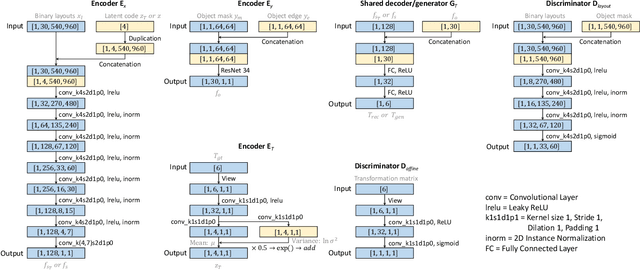
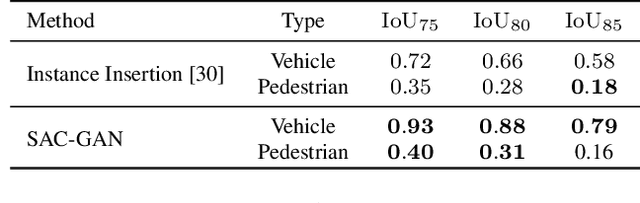

We present a compositional approach to image augmentation for self-driving applications. It is an end-to-end neural network that is trained to seamlessly compose an object (e.g., a vehicle or pedestrian) represented as a cropped patch from an object image, into a background scene image. As our approach emphasizes more on semantic and structural coherence of the composed images, rather than their pixel-level RGB accuracies, we tailor the input and output of our network with structure-aware features and design our network losses accordingly. Specifically, our network takes the semantic layout features from the input scene image, features encoded from the edges and silhouette in the input object patch, as well as a latent code as inputs, and generates a 2D spatial affine transform defining the translation and scaling of the object patch. The learned parameters are further fed into a differentiable spatial transformer network to transform the object patch into the target image, where our model is trained adversarially using an affine transform discriminator and a layout discriminator. We evaluate our network, coined SAC-GAN for structure-aware composition, on prominent self-driving datasets in terms of quality, composability, and generalizability of the composite images. Comparisons are made to state-of-the-art alternatives, confirming superiority of our method.