 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVT-CLIP: Enhancing Vision-Language Models with Visual-guided Texts
Paper and Code
Dec 04, 2021

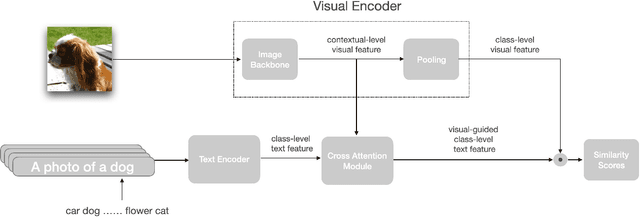
Contrastive Vision-Language Pre-training (CLIP) has drown increasing attention recently for its transferable visual representation learning. Supervised by large-scale image-text pairs, CLIP is able to align paired images and texts and thus conduct zero-shot recognition in open-vocabulary scenarios. However, there exists semantic gap between the specific application and generally pre-trained knowledge, which makes the matching sub-optimal on downstream tasks. In this paper, we propose VT-CLIP to enhance vision-language modeling via visual-guided texts. Specifically, we guide the text feature to adaptively explore informative regions on the image and aggregate the visual feature by cross-attention machanism. In this way, the visual-guided text become more semantically correlated with the image, which greatly benefits the matching process. In few-shot settings, we evaluate our VT-CLIP on 11 well-known classification datasets and experiment extensive ablation studies to demonstrate the effectiveness of VT-CLIP. The code will be released soon.