 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Scenes from Novel Viewpoints
Paper and Code
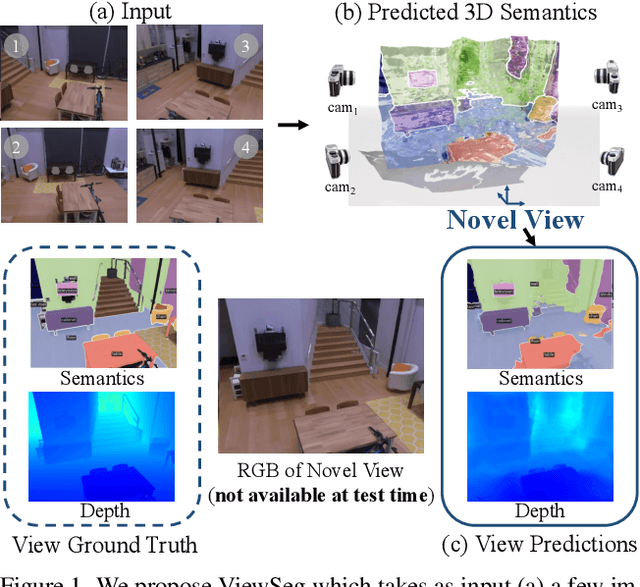

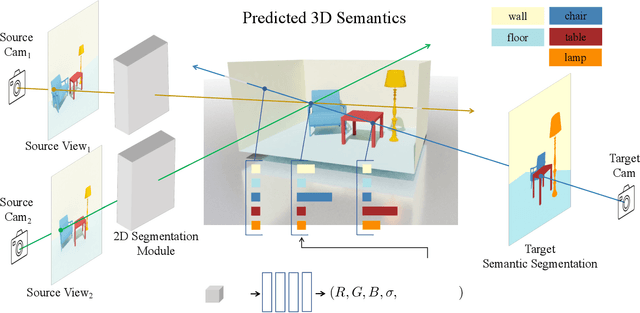

Humans can perceive scenes in 3D from a handful of 2D views. For AI agents, the ability to recognize a scene from any viewpoint given only a few images enables them to efficiently interact with the scene and its objects. In this work, we attempt to endow machines with this ability. We propose a model which takes as input a few RGB images of a new scene and recognizes the scene from novel viewpoints by segmenting it into semantic categories. All this without access to the RGB images from those views. We pair 2D scene recognition with an implicit 3D representation and learn from multi-view 2D annotations of hundreds of scenes without any 3D supervision beyond camera poses. We experiment on challenging datasets and demonstrate our model's ability to jointly capture semantics and geometry of novel scenes with diverse layouts, object types and shapes.