 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition
Paper and Code
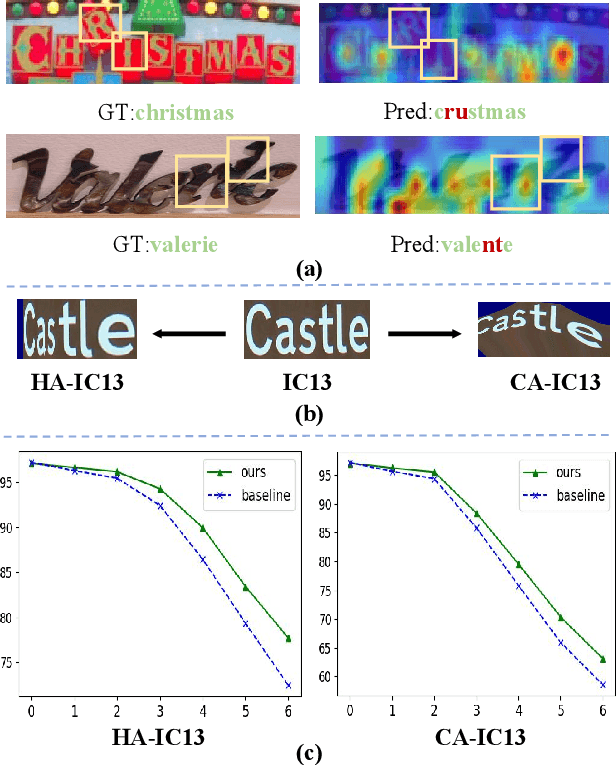
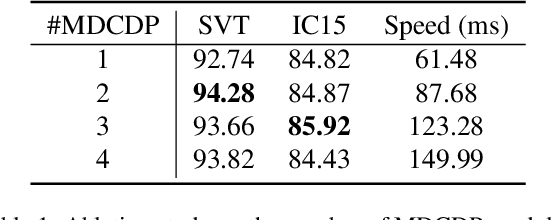
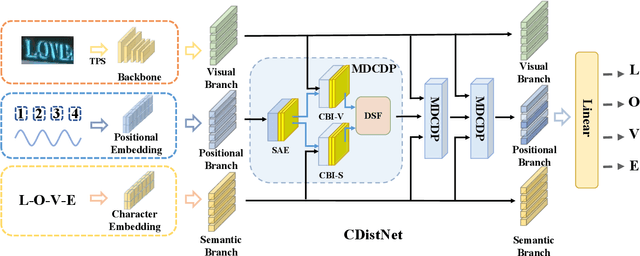
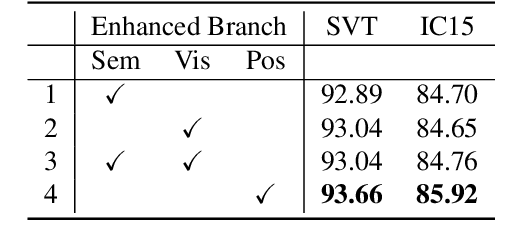
The attention-based encoder-decoder framework is becoming popular in scene text recognition, largely due to its superiority in integrating recognition clues from both visual and semantic domains. However, recent studies show the two clues might be misaligned in the difficult text (e.g., with rare text shapes) and introduce constraints such as character position to alleviate the problem. Despite certain success, a content-free positional embedding hardly associates with meaningful local image regions stably. In this paper, we propose a novel module called Multi-Domain Character Distance Perception (MDCDP) to establish a visual and semantic related position encoding. MDCDP uses positional embedding to query both visual and semantic features following the attention mechanism. It naturally encodes the positional clue, which describes both visual and semantic distances among characters. We develop a novel architecture named CDistNet that stacks MDCDP several times to guide precise distance modeling. Thus, the visual-semantic alignment is well built even various difficulties presented. We apply CDistNet to two augmented datasets and six public benchmarks. The experiments demonstrate that CDistNet achieves state-of-the-art recognition accuracy. While the visualization also shows that CDistNet achieves proper attention localization in both visual and semantic domains. We will release our code upon acceptance.