 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-sparsity DNN: Fast Sparsity Optimization for On-Device Streaming E2E ASR via Supernet
Paper and Code
Oct 15, 2021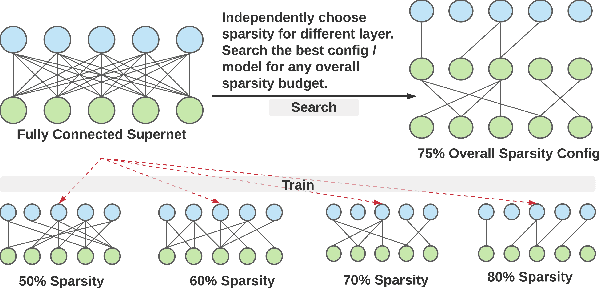
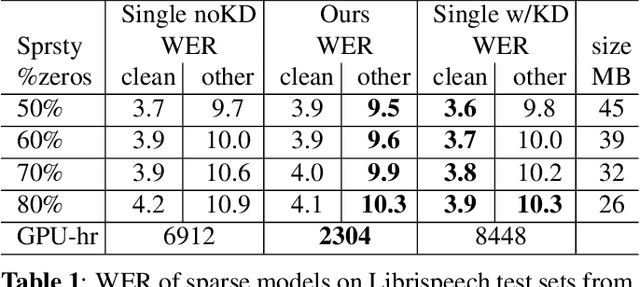
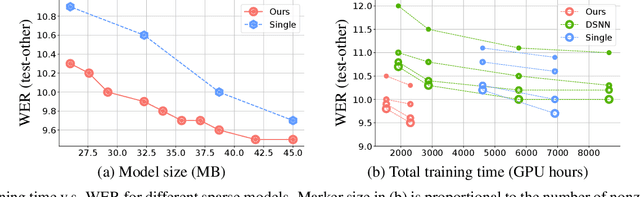
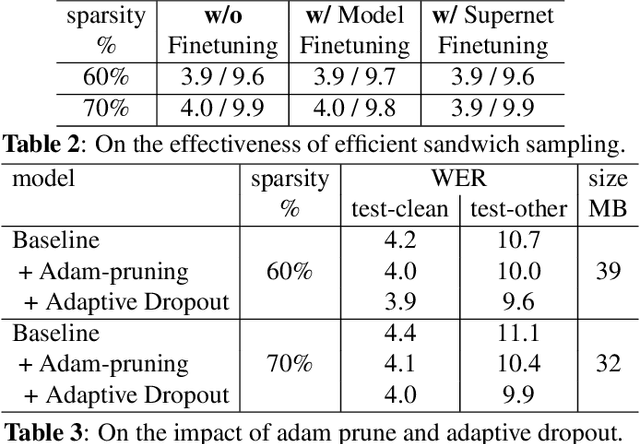
From wearables to powerful smart devices, modern automatic speech recognition (ASR) models run on a variety of edge devices with different computational budgets. To navigate the Pareto front of model accuracy vs model size, researchers are trapped in a dilemma of optimizing model accuracy by training and fine-tuning models for each individual edge device while keeping the training GPU-hours tractable. In this paper, we propose Omni-sparsity DNN, where a single neural network can be pruned to generate optimized model for a large range of model sizes. We develop training strategies for Omni-sparsity DNN that allows it to find models along the Pareto front of word-error-rate (WER) vs model size while keeping the training GPU-hours to no more than that of training one singular model. We demonstrate the Omni-sparsity DNN with streaming E2E ASR models. Our results show great saving on training time and resources with similar or better accuracy on LibriSpeech compared to individually pruned sparse models: 2%-6.6% better WER on Test-other.