 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTraTA: Self-Training with Task Augmentation for Better Few-shot Learning
Paper and Code
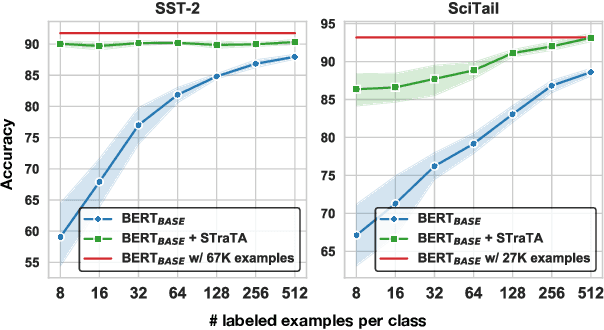
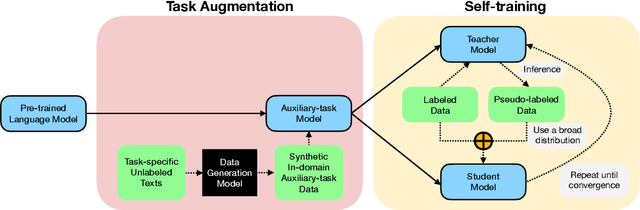
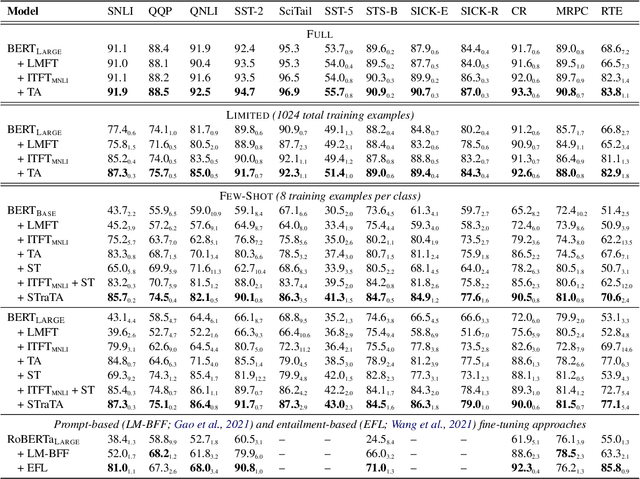
Despite their recent successes in tackling many NLP tasks, large-scale pre-trained language models do not perform as well in few-shot settings where only a handful of training examples are available. To address this shortcoming, we propose STraTA, which stands for Self-Training with Task Augmentation, an approach that builds on two key ideas for effective leverage of unlabeled data. First, STraTA uses task augmentation, a novel technique that synthesizes a large amount of data for auxiliary-task fine-tuning from target-task unlabeled texts. Second, STraTA performs self-training by further fine-tuning the strong base model created by task augmentation on a broad distribution of pseudo-labeled data. Our experiments demonstrate that STraTA can substantially improve sample efficiency across 12 few-shot benchmarks. Remarkably, on the SST-2 sentiment dataset, STraTA, with only 8 training examples per class, achieves comparable results to standard fine-tuning with 67K training examples. Our analyses reveal that task augmentation and self-training are both complementary and independently effective.