 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVOQUER: Enhancing Temporal Grounding with Video-Pivoted BackQuery Generation
Paper and Code
Sep 10, 2021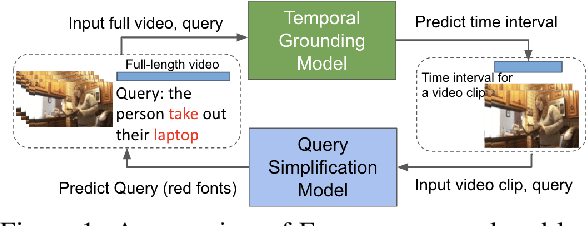
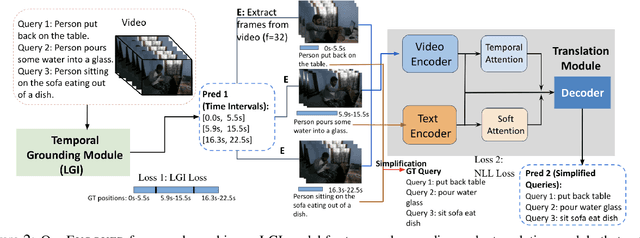
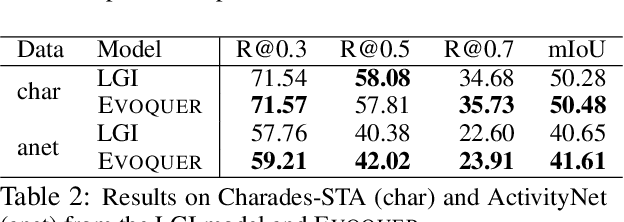
Temporal grounding aims to predict a time interval of a video clip corresponding to a natural language query input. In this work, we present EVOQUER, a temporal grounding framework incorporating an existing text-to-video grounding model and a video-assisted query generation network. Given a query and an untrimmed video, the temporal grounding model predicts the target interval, and the predicted video clip is fed into a video translation task by generating a simplified version of the input query. EVOQUER forms closed-loop learning by incorporating loss functions from both temporal grounding and query generation serving as feedback. Our experiments on two widely used datasets, Charades-STA and ActivityNet, show that EVOQUER achieves promising improvements by 1.05 and 1.31 at R@0.7. We also discuss how the query generation task could facilitate error analysis by explaining temporal grounding model behavior.