 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-autoregressive End-to-end Speech Translation with Parallel Autoregressive Rescoring
Paper and Code
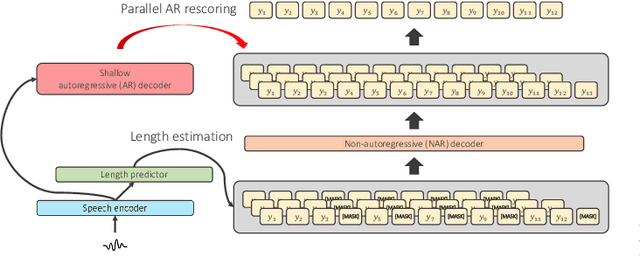
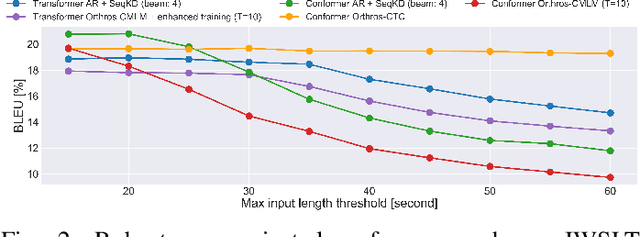
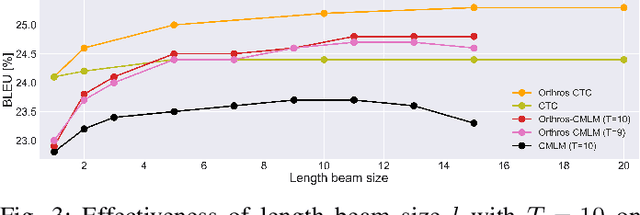
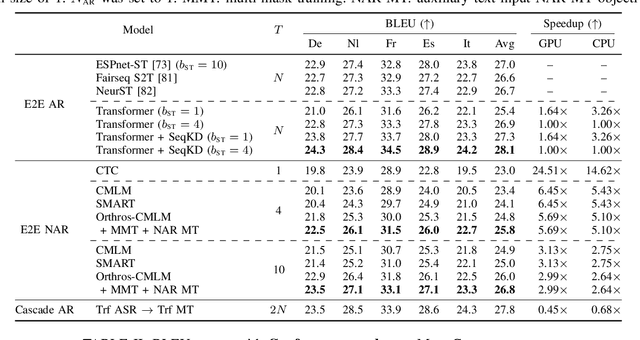
This article describes an efficient end-to-end speech translation (E2E-ST) framework based on non-autoregressive (NAR) models. End-to-end speech translation models have several advantages over traditional cascade systems such as inference latency reduction. However, conventional AR decoding methods are not fast enough because each token is generated incrementally. NAR models, however, can accelerate the decoding speed by generating multiple tokens in parallel on the basis of the token-wise conditional independence assumption. We propose a unified NAR E2E-ST framework called Orthros, which has an NAR decoder and an auxiliary shallow AR decoder on top of the shared encoder. The auxiliary shallow AR decoder selects the best hypothesis by rescoring multiple candidates generated from the NAR decoder in parallel (parallel AR rescoring). We adopt conditional masked language model (CMLM) and a connectionist temporal classification (CTC)-based model as NAR decoders for Orthros, referred to as Orthros-CMLM and Orthros-CTC, respectively. We also propose two training methods to enhance the CMLM decoder. Experimental evaluations on three benchmark datasets with six language directions demonstrated that Orthros achieved large improvements in translation quality with a very small overhead compared with the baseline NAR model. Moreover, the Conformer encoder architecture enabled large quality improvements, especially for CTC-based models. Orthros-CTC with the Conformer encoder increased decoding speed by 3.63x on CPU with translation quality comparable to that of an AR model.