 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRendezvous: Attention Mechanisms for the Recognition of Surgical Action Triplets in Endoscopic Videos
Paper and Code
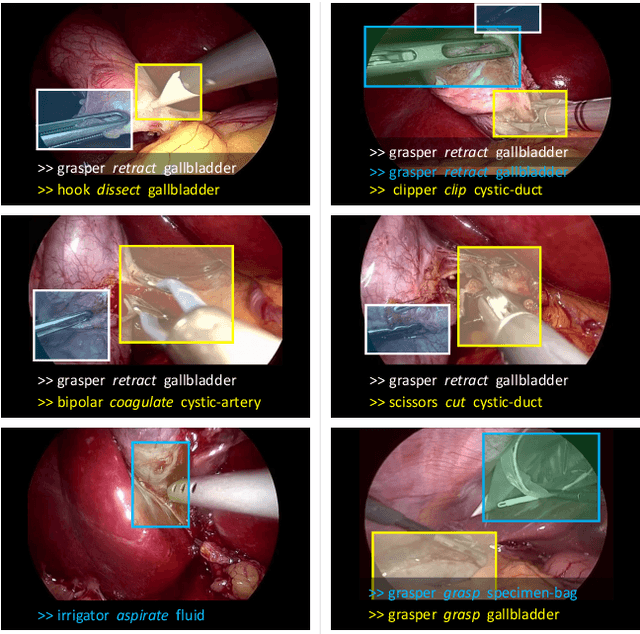
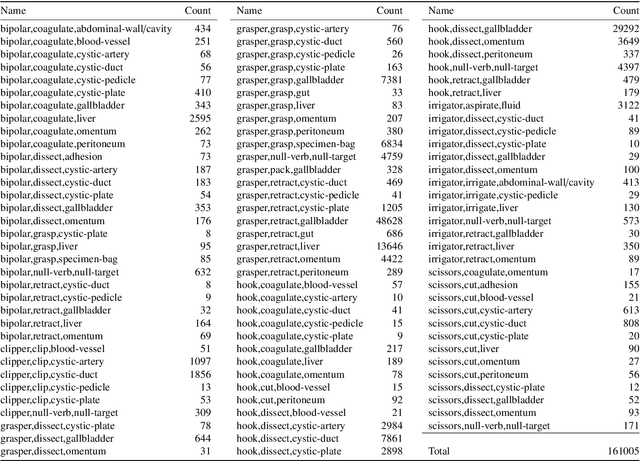
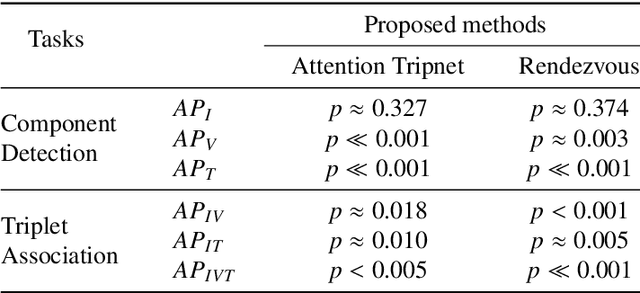
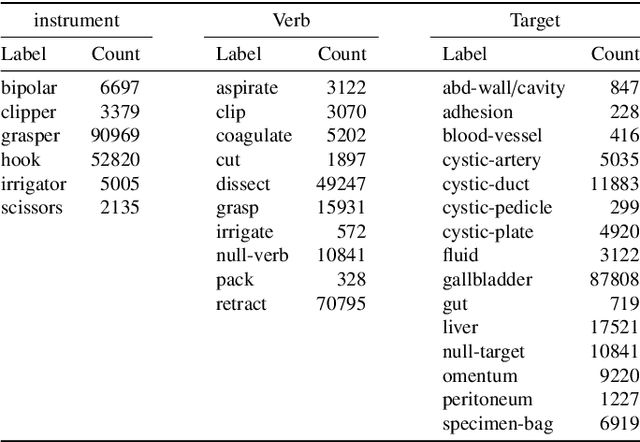
Out of all existing frameworks for surgical workflow analysis in endoscopic videos, action triplet recognition stands out as the only one aiming to provide truly fine-grained and comprehensive information on surgical activities. This information, presented as <instrument, verb, target> combinations, is highly challenging to be accurately identified. Triplet components can be difficult to recognize individually; in this task, it requires not only performing recognition simultaneously for all three triplet components, but also correctly establishing the data association between them. To achieve this task, we introduce our new model, the Rendezvous (RDV), which recognizes triplets directly from surgical videos by leveraging attention at two different levels. We first introduce a new form of spatial attention to capture individual action triplet components in a scene; called the Class Activation Guided Attention Mechanism (CAGAM). This technique focuses on the recognition of verbs and targets using activations resulting from instruments. To solve the association problem, our RDV model adds a new form of semantic attention inspired by Transformer networks. Using multiple heads of cross and self attentions, RDV is able to effectively capture relationships between instruments, verbs, and targets. We also introduce CholecT50 - a dataset of 50 endoscopic videos in which every frame has been annotated with labels from 100 triplet classes. Our proposed RDV model significantly improves the triplet prediction mAP by over 9% compared to the state-of-the-art methods on this dataset.