 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning for Time-varying Networks: A Scalable Design
Paper and Code
Jul 31, 2021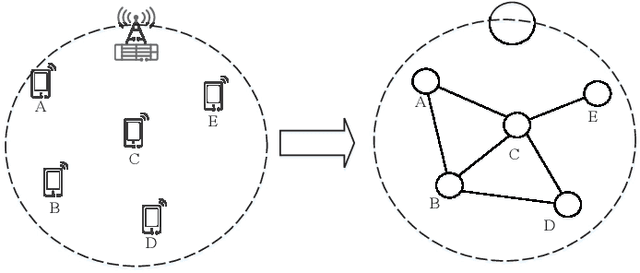
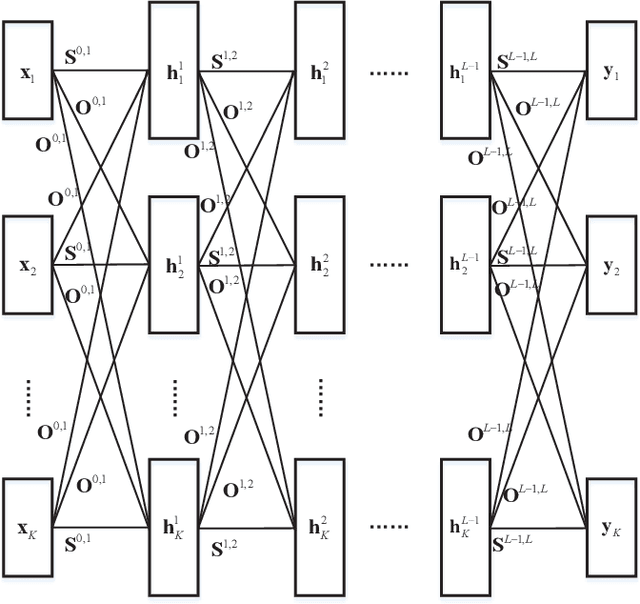
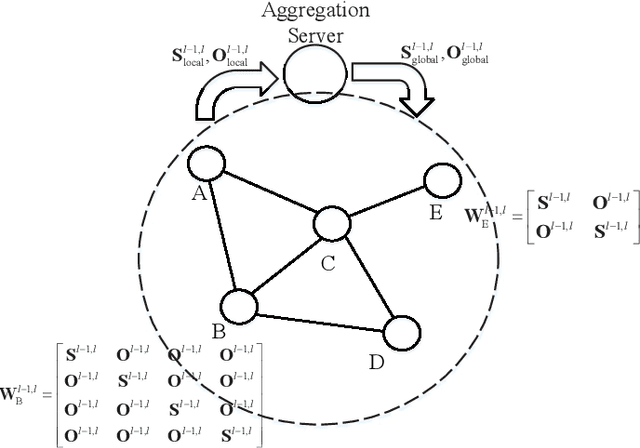
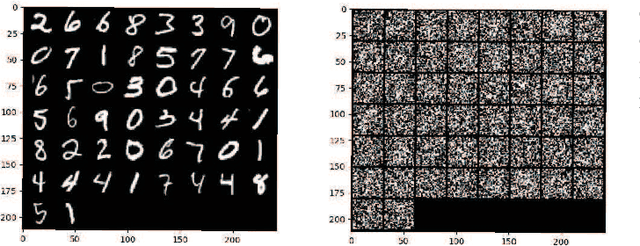
The wireless network is undergoing a trend from "onnection of things" to "connection of intelligence". With data spread over the communication networks and computing capability enhanced on the devices, distributed learning becomes a hot topic in both industrial and academic communities. Many frameworks, such as federated learning and federated distillation, have been proposed. However, few of them takes good care of obstacles such as the time-varying topology resulted by the characteristics of wireless networks. In this paper, we propose a distributed learning framework based on a scalable deep neural network (DNN) design. By exploiting the permutation equivalence and invariance properties of the learning tasks, the DNNs with different scales for different clients can be built up based on two basic parameter sub-matrices. Further, model aggregation can also be conducted based on these two sub-matrices to improve the learning convergence and performance. Finally, simulation results verify the benefits of the proposed framework by compared with some baselines.