 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for Hierarchical Vision Transformer?
Paper and Code
Jul 05, 2021
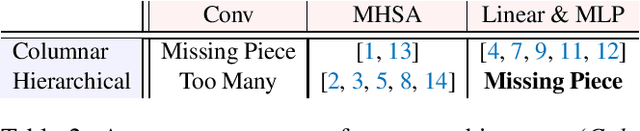


Recent studies show that hierarchical Vision Transformer with interleaved non-overlapped intra window self-attention \& shifted window self-attention is able to achieve state-of-the-art performance in various visual recognition tasks and challenges CNN's dense sliding window paradigm. Most follow-up works try to replace shifted window operation with other kinds of cross window communication while treating self-attention as the de-facto standard for intra window information aggregation. In this short preprint, we question whether self-attention is the only choice for hierarchical Vision Transformer to attain strong performance, and what makes for hierarchical Vision Transformer? We replace self-attention layers in Swin Transformer and Shuffle Transformer with simple linear mapping and keep other components unchanged. The resulting architecture with 25.4M parameters and 4.2G FLOPs achieves 80.5\% Top-1 accuracy, compared to 81.3\% for Swin Transformer with 28.3M parameters and 4.5G FLOPs. We also experiment with other alternatives to self-attention for context aggregation inside each non-overlapped window, which all give similar competitive results under the same architecture. Our study reveals that the \textbf{macro architecture} of Swin model families (i.e., interleaved intra window \& cross window communications), other than specific aggregation layers or specific means of cross window communication, may be more responsible for its strong performance and is the real challenger to CNN's dense sliding window paradigm.