 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding
Paper and Code

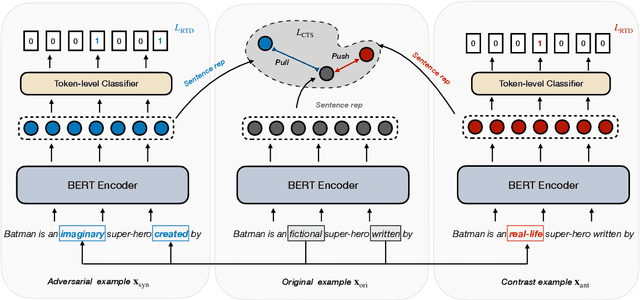

Despite pre-trained language models have proven useful for learning high-quality semantic representations, these models are still vulnerable to simple perturbations. Recent works aimed to improve the robustness of pre-trained models mainly focus on adversarial training from perturbed examples with similar semantics, neglecting the utilization of different or even opposite semantics. Different from the image processing field, the text is discrete and few word substitutions can cause significant semantic changes. To study the impact of semantics caused by small perturbations, we conduct a series of pilot experiments and surprisingly find that adversarial training is useless or even harmful for the model to detect these semantic changes. To address this problem, we propose Contrastive Learning with semantIc Negative Examples (CLINE), which constructs semantic negative examples unsupervised to improve the robustness under semantically adversarial attacking. By comparing with similar and opposite semantic examples, the model can effectively perceive the semantic changes caused by small perturbations. Empirical results show that our approach yields substantial improvements on a range of sentiment analysis, reasoning, and reading comprehension tasks. And CLINE also ensures the compactness within the same semantics and separability across different semantics in sentence-level.