 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Dynamics and $Φ$-Regret Minimization in Games
Paper and Code
Jun 28, 2021
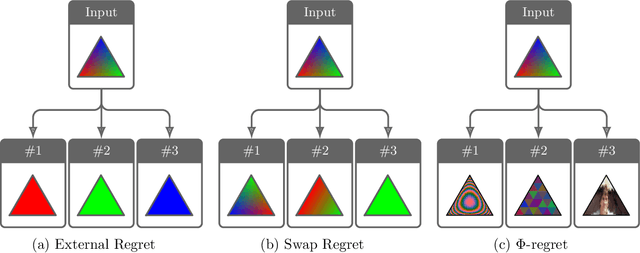
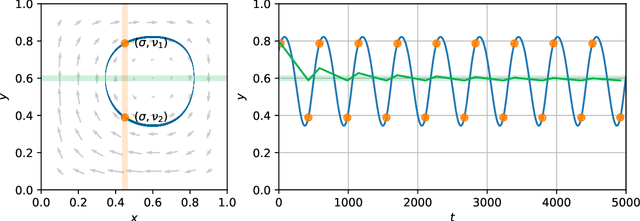
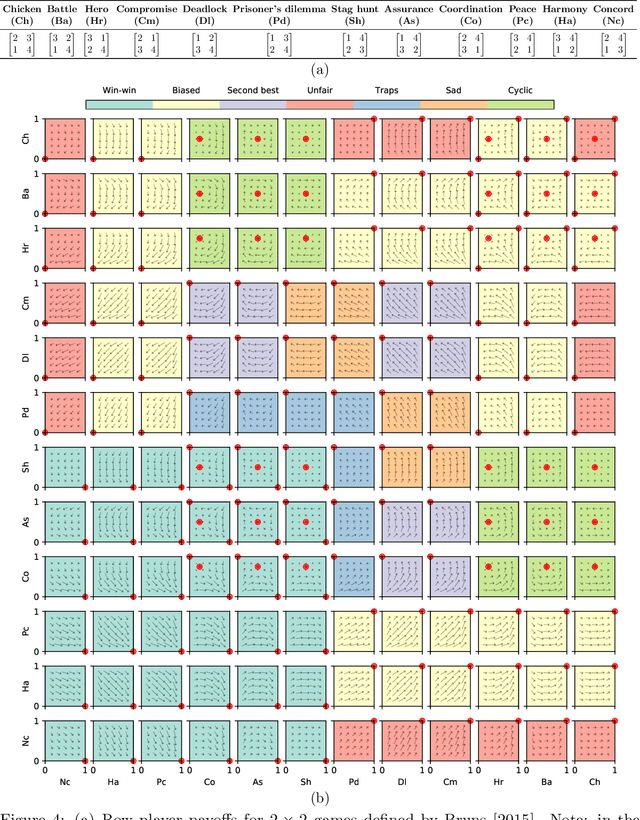
Regret has been established as a foundational concept in online learning, and likewise has important applications in the analysis of learning dynamics in games. Regret quantifies the difference between a learner's performance against a baseline in hindsight. It is well-known that regret-minimizing algorithms converge to certain classes of equilibria in games; however, traditional forms of regret used in game theory predominantly consider baselines that permit deviations to deterministic actions or strategies. In this paper, we revisit our understanding of regret from the perspective of deviations over partitions of the full \emph{mixed} strategy space (i.e., probability distributions over pure strategies), under the lens of the previously-established $\Phi$-regret framework, which provides a continuum of stronger regret measures. Importantly, $\Phi$-regret enables learning agents to consider deviations from and to mixed strategies, generalizing several existing notions of regret such as external, internal, and swap regret, and thus broadening the insights gained from regret-based analysis of learning algorithms. We prove here that the well-studied evolutionary learning algorithm of replicator dynamics (RD) seamlessly minimizes the strongest possible form of $\Phi$-regret in generic $2 \times 2$ games, without any modification of the underlying algorithm itself. We subsequently conduct experiments validating our theoretical results in a suite of 144 $2 \times 2$ games wherein RD exhibits a diverse set of behaviors. We conclude by providing empirical evidence of $\Phi$-regret minimization by RD in some larger games, hinting at further opportunity for $\Phi$-regret based study of such algorithms from both a theoretical and empirical perspective.