 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Legal Citation Recommendation using Deep Learning
Paper and Code
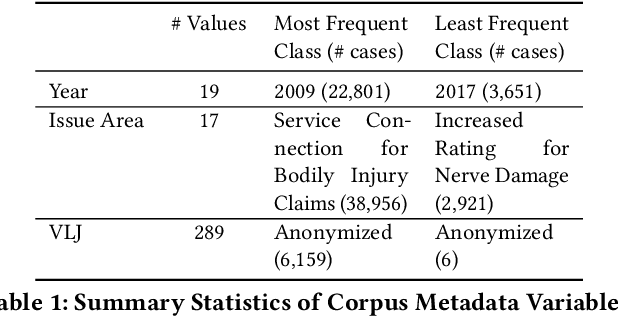
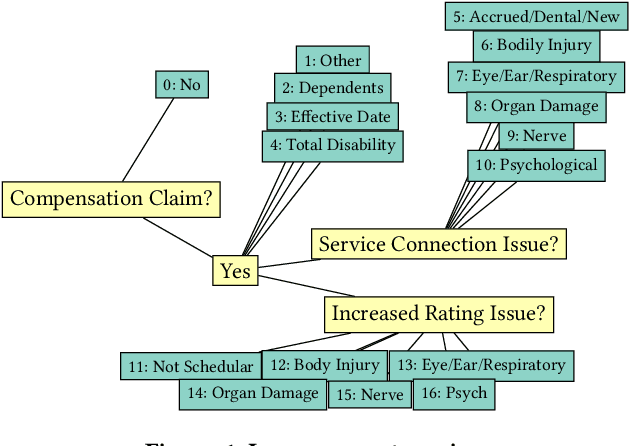
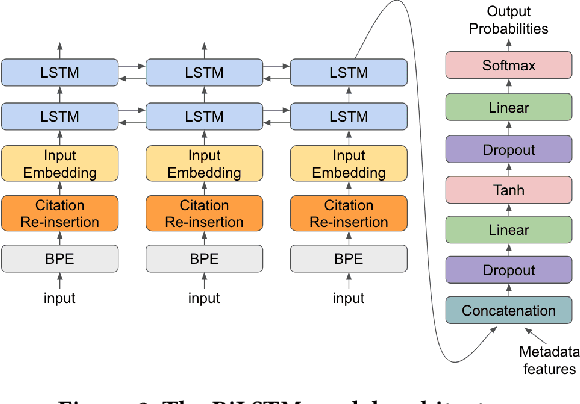
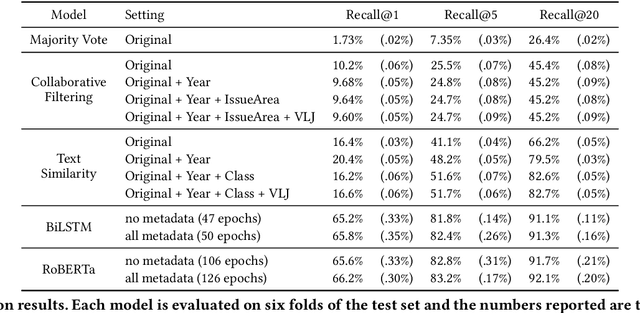
Lawyers and judges spend a large amount of time researching the proper legal authority to cite while drafting decisions. In this paper, we develop a citation recommendation tool that can help improve efficiency in the process of opinion drafting. We train four types of machine learning models, including a citation-list based method (collaborative filtering) and three context-based methods (text similarity, BiLSTM and RoBERTa classifiers). Our experiments show that leveraging local textual context improves recommendation, and that deep neural models achieve decent performance. We show that non-deep text-based methods benefit from access to structured case metadata, but deep models only benefit from such access when predicting from context of insufficient length. We also find that, even after extensive training, RoBERTa does not outperform a recurrent neural model, despite its benefits of pretraining. Our behavior analysis of the RoBERTa model further shows that predictive performance is stable across time and citation classes.