 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multilingual Representation for Natural Language Understanding with Enhanced Cross-Lingual Supervision
Paper and Code
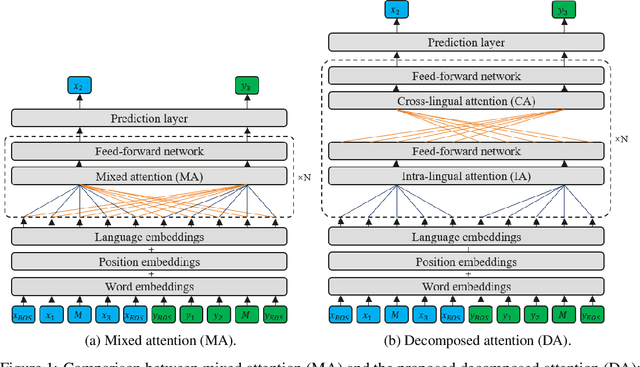

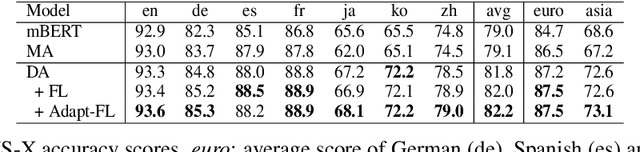
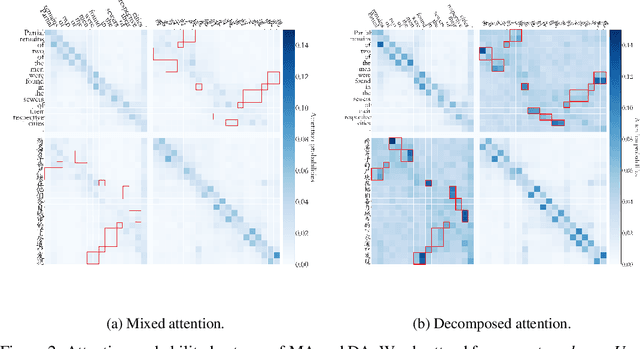
Recently, pre-training multilingual language models has shown great potential in learning multilingual representation, a crucial topic of natural language processing. Prior works generally use a single mixed attention (MA) module, following TLM (Conneau and Lample, 2019), for attending to intra-lingual and cross-lingual contexts equivalently and simultaneously. In this paper, we propose a network named decomposed attention (DA) as a replacement of MA. The DA consists of an intra-lingual attention (IA) and a cross-lingual attention (CA), which model intralingual and cross-lingual supervisions respectively. In addition, we introduce a language-adaptive re-weighting strategy during training to further boost the model's performance. Experiments on various cross-lingual natural language understanding (NLU) tasks show that the proposed architecture and learning strategy significantly improve the model's cross-lingual transferability.