 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Slice-Aware Representations with Mixture of Attentions
Paper and Code
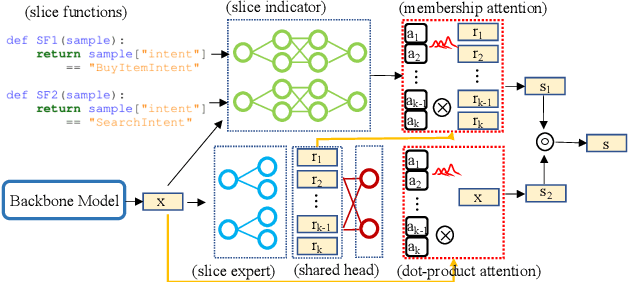

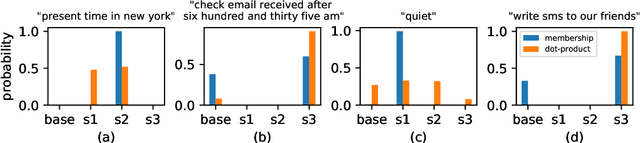
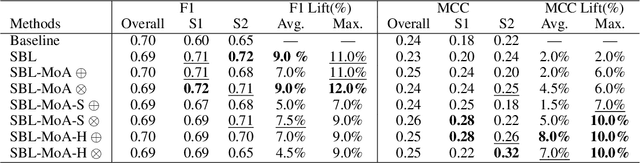
Real-world machine learning systems are achieving remarkable performance in terms of coarse-grained metrics like overall accuracy and F-1 score. However, model improvement and development often require fine-grained modeling on individual data subsets or slices, for instance, the data slices where the models have unsatisfactory results. In practice, it gives tangible values for developing such models that can pay extra attention to critical or interested slices while retaining the original overall performance. This work extends the recent slice-based learning (SBL)~\cite{chen2019slice} with a mixture of attentions (MoA) to learn slice-aware dual attentive representations. We empirically show that the MoA approach outperforms the baseline method as well as the original SBL approach on monitored slices with two natural language understanding (NLU) tasks.