 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model as an Annotator: Exploring DialoGPT for Dialogue Summarization
Paper and Code

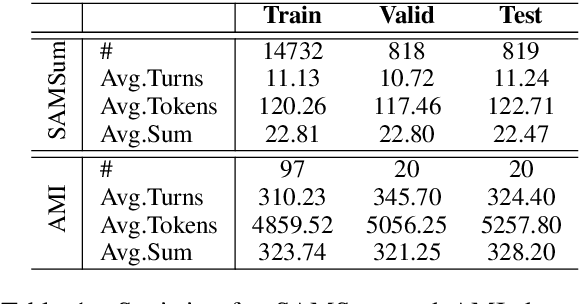
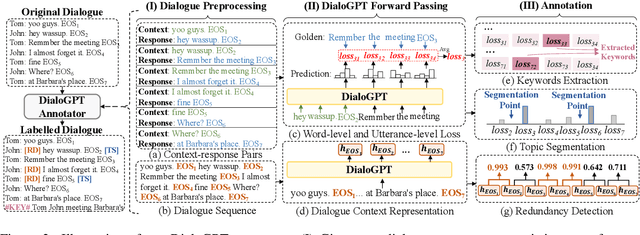
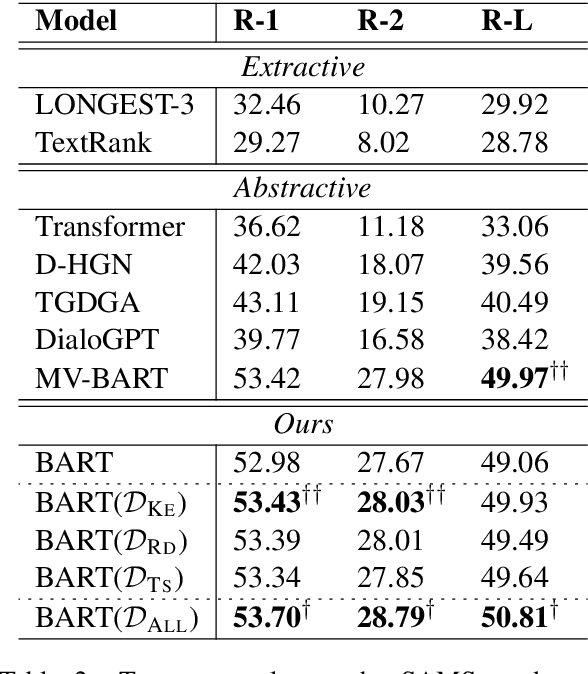
Current dialogue summarization systems usually encode the text with a number of general semantic features (e.g., keywords and topics) to gain more powerful dialogue modeling capabilities. However, these features are obtained via open-domain toolkits that are dialog-agnostic or heavily relied on human annotations. In this paper, we show how DialoGPT, a pre-trained model for conversational response generation, can be developed as an unsupervised dialogue annotator, which takes advantage of dialogue background knowledge encoded in DialoGPT. We apply DialoGPT to label three types of features on two dialogue summarization datasets, SAMSum and AMI, and employ pre-trained and non pre-trained models as our summarizes. Experimental results show that our proposed method can obtain remarkable improvements on both datasets and achieves new state-of-the-art performance on the SAMSum dataset.