 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKilling Two Birds with One Stone: Stealing Model and Inferring Attribute from BERT-based APIs
Paper and Code
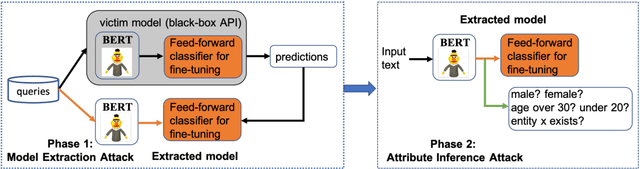
The advances in pre-trained models (e.g., BERT, XLNET and etc) have largely revolutionized the predictive performance of various modern natural language processing tasks. This allows corporations to provide machine learning as a service (MLaaS) by encapsulating fine-tuned BERT-based models as commercial APIs. However, previous works have discovered a series of vulnerabilities in BERT- based APIs. For example, BERT-based APIs are vulnerable to both model extraction attack and adversarial example transferrability attack. However, due to the high capacity of BERT-based APIs, the fine-tuned model is easy to be overlearned, what kind of information can be leaked from the extracted model remains unknown and is lacking. To bridge this gap, in this work, we first present an effective model extraction attack, where the adversary can practically steal a BERT-based API (the target/victim model) by only querying a limited number of queries. We further develop an effective attribute inference attack to expose the sensitive attribute of the training data used by the BERT-based APIs. Our extensive experiments on benchmark datasets under various realistic settings demonstrate the potential vulnerabilities of BERT-based APIs.