 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Detection Between Vehicles and Vulnerable Road Users: A Deep Generative Approach with Attention
Paper and Code
May 09, 2021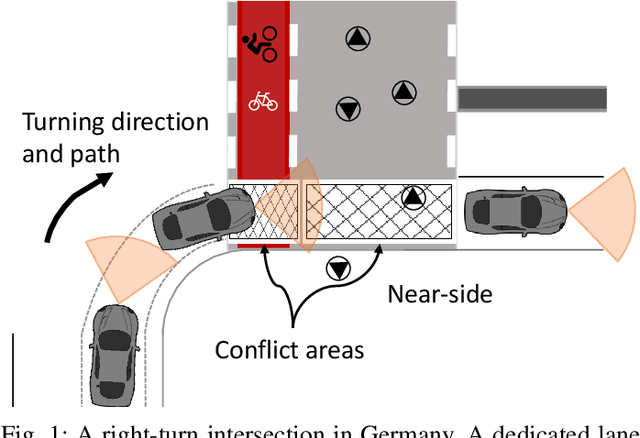
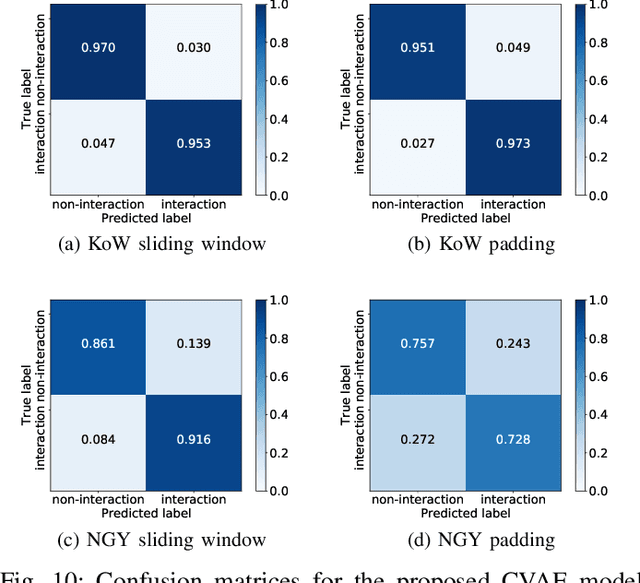
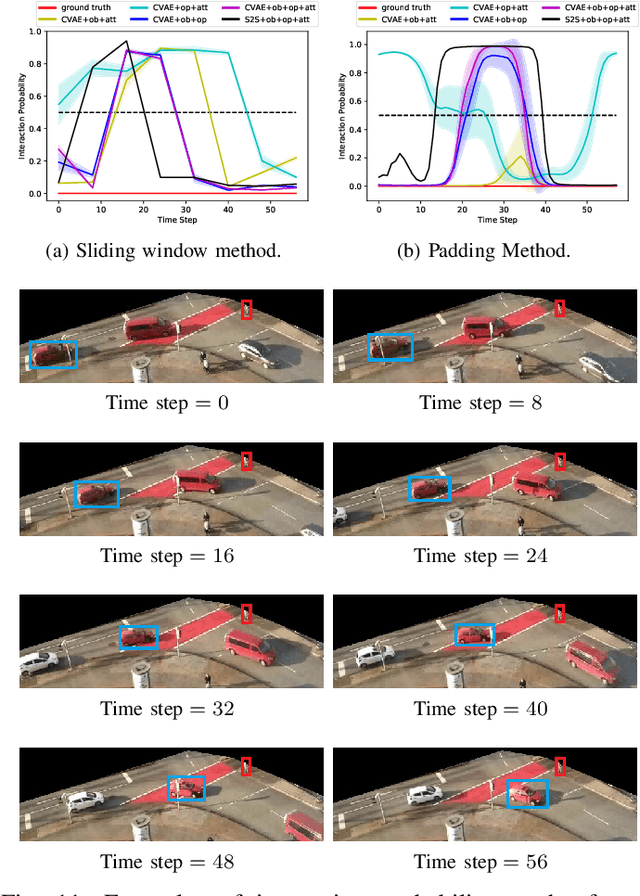
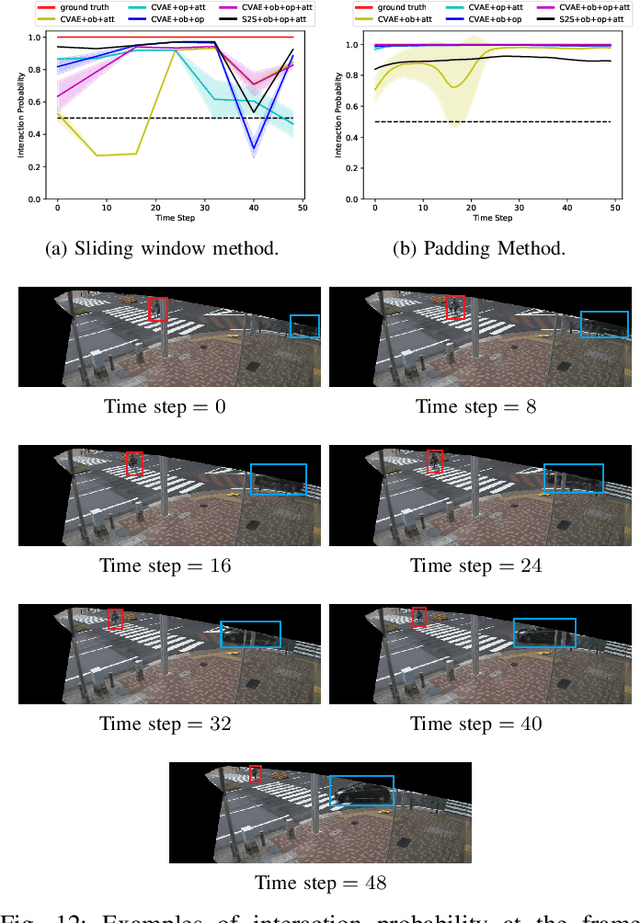
Intersections where vehicles are permitted to turn and interact with vulnerable road users (VRUs) like pedestrians and cyclists are among some of the most challenging locations for automated and accurate recognition of road users' behavior. In this paper, we propose a deep conditional generative model for interaction detection at such locations. It aims to automatically analyze massive video data about the continuity of road users' behavior. This task is essential for many intelligent transportation systems such as traffic safety control and self-driving cars that depend on the understanding of road users' locomotion. A Conditional Variational Auto-Encoder based model with Gaussian latent variables is trained to encode road users' behavior and perform probabilistic and diverse predictions of interactions. The model takes as input the information of road users' type, position and motion automatically extracted by a deep learning object detector and optical flow from videos, and generates frame-wise probabilities that represent the dynamics of interactions between a turning vehicle and any VRUs involved. The model's efficacy was validated by testing on real--world datasets acquired from two different intersections. It achieved an F1-score above 0.96 at a right--turn intersection in Germany and 0.89 at a left--turn intersection in Japan, both with very busy traffic flows.