 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Authors Matter: Understanding and Mitigating Implicit Bias in Deep Text Classification
Paper and Code

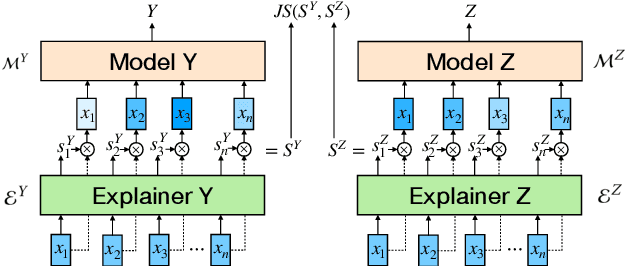
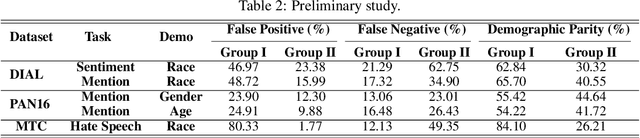
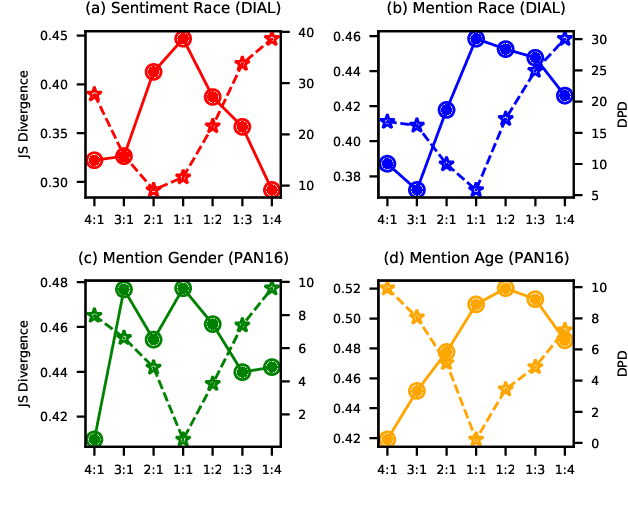
It is evident that deep text classification models trained on human data could be biased. In particular, they produce biased outcomes for texts that explicitly include identity terms of certain demographic groups. We refer to this type of bias as explicit bias, which has been extensively studied. However, deep text classification models can also produce biased outcomes for texts written by authors of certain demographic groups. We refer to such bias as implicit bias of which we still have a rather limited understanding. In this paper, we first demonstrate that implicit bias exists in different text classification tasks for different demographic groups. Then, we build a learning-based interpretation method to deepen our knowledge of implicit bias. Specifically, we verify that classifiers learn to make predictions based on language features that are related to the demographic attributes of the authors. Next, we propose a framework Debiased-TC to train deep text classifiers to make predictions on the right features and consequently mitigate implicit bias. We conduct extensive experiments on three real-world datasets. The results show that the text classification models trained under our proposed framework outperform traditional models significantly in terms of fairness, and also slightly in terms of classification performance.