 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Sparsification of Neural Networks with Global Sparsity Constraint
Paper and Code
May 03, 2021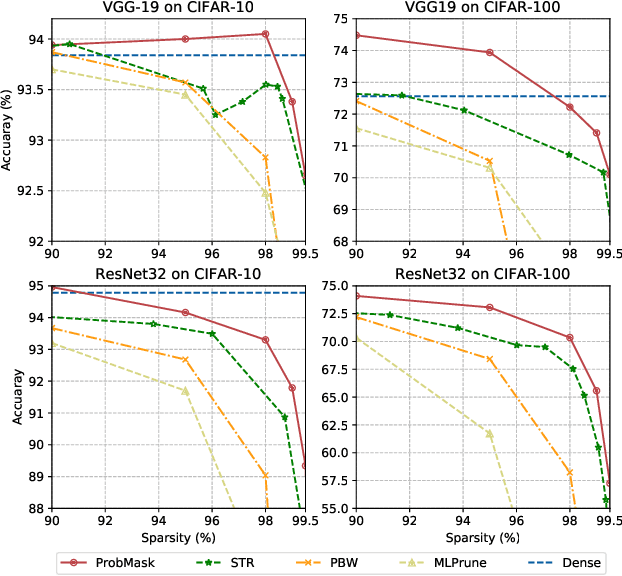
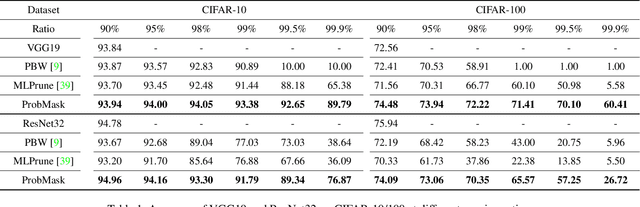
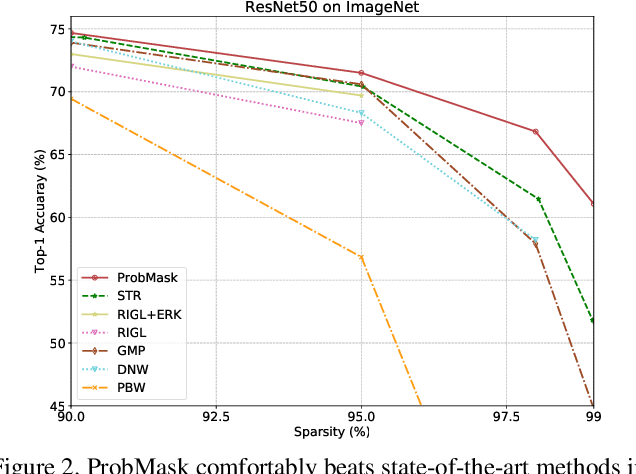
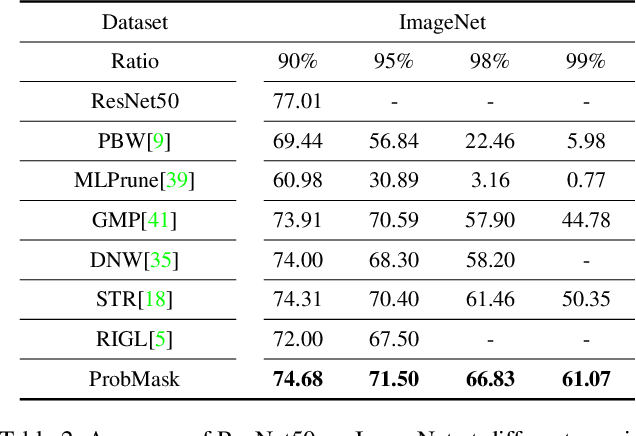
Weight pruning is an effective technique to reduce the model size and inference time for deep neural networks in real-world deployments. However, since magnitudes and relative importance of weights are very different for different layers of a neural network, existing methods rely on either manual tuning or handcrafted heuristic rules to find appropriate pruning rates individually for each layer. This approach generally leads to suboptimal performance. In this paper, by directly working on the probability space, we propose an effective network sparsification method called {\it probabilistic masking} (ProbMask), which solves a natural sparsification formulation under global sparsity constraint. The key idea is to use probability as a global criterion for all layers to measure the weight importance. An appealing feature of ProbMask is that the amounts of weight redundancy can be learned automatically via our constraint and thus we avoid the problem of tuning pruning rates individually for different layers in a network. Extensive experimental results on CIFAR-10/100 and ImageNet demonstrate that our method is highly effective, and can outperform previous state-of-the-art methods by a significant margin, especially in the high pruning rate situation. Notably, the gap of Top-1 accuracy between our ProbMask and existing methods can be up to 10\%. As a by-product, we show ProbMask is also highly effective in identifying supermasks, which are subnetworks with high performance in a randomly weighted dense neural network.