 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Inefficiency of Self-supervised Representation Learning
Paper and Code
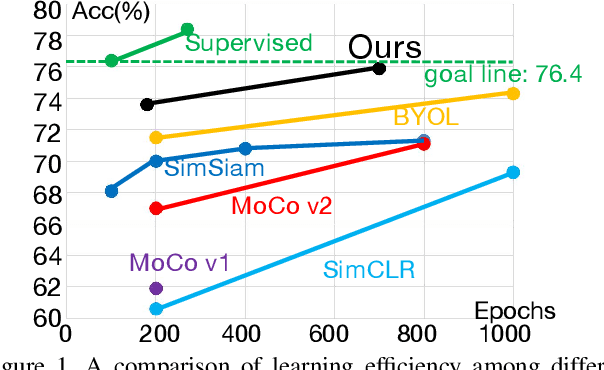
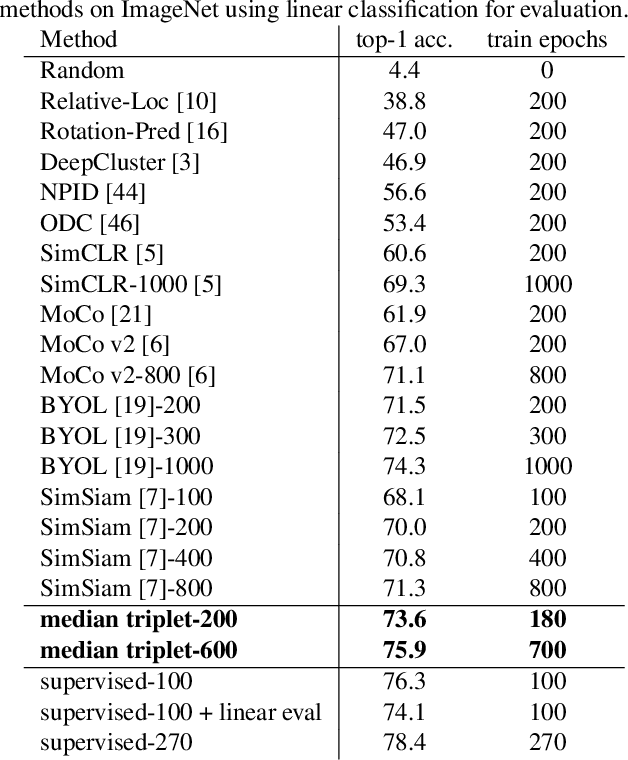
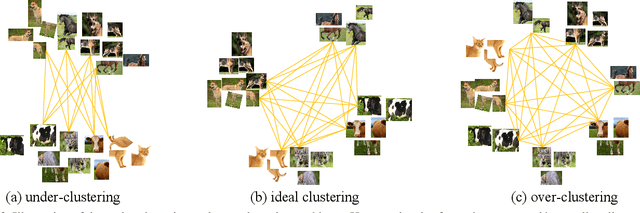
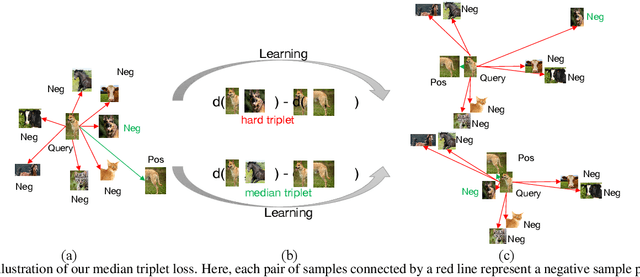
Self-supervised learning has attracted great interest due to its tremendous potentials in learning discriminative representations in an unsupervised manner. Along this direction, contrastive learning achieves current state-of-the-art performance. Despite the acknowledged successes, existing contrastive learning methods suffer from very low learning efficiency, e.g., taking about ten times more training epochs than supervised learning for comparable recognition accuracy. In this paper, we discover two contradictory phenomena in contrastive learning that we call under-clustering and over-clustering problems, which are major obstacles to learning efficiency. Under-clustering means that the model cannot efficiently learn to discover the dissimilarity between inter-class samples when the negative sample pairs for contrastive learning are insufficient to differentiate all the actual object categories. Over-clustering implies that the model cannot efficiently learn the feature representation from excessive negative sample pairs, which include many outliers and thus enforce the model to over-cluster samples of the same actual categories into different clusters. To simultaneously overcome these two problems, we propose a novel self-supervised learning framework using a median triplet loss. Precisely, we employ a triplet loss tending to maximize the relative distance between the positive pair and negative pairs to address the under-clustering problem; and we construct the negative pair by selecting the negative sample of a median similarity score from all negative samples to avoid the over-clustering problem, guaranteed by the Bernoulli Distribution model. We extensively evaluate our proposed framework in several large-scale benchmarks (e.g., ImageNet, SYSU-30k, and COCO). The results demonstrate the superior performance of our model over the latest state-of-the-art methods by a clear margin.