 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Deep Learning for Joint Audio-Visual Lip Biometrics
Paper and Code

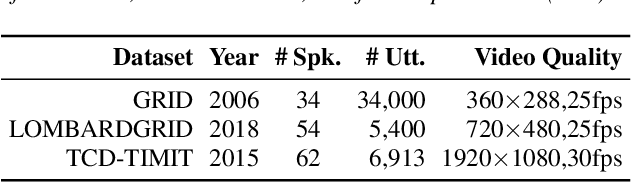
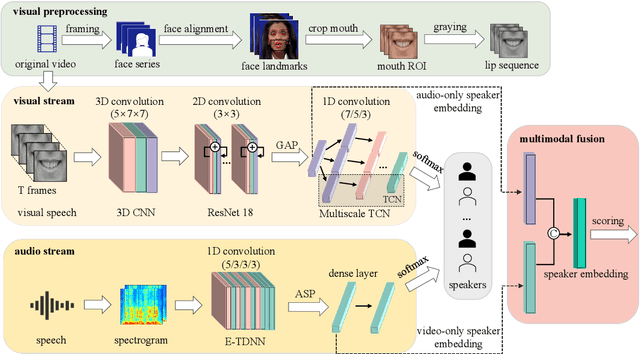

Audio-visual (AV) lip biometrics is a promising authentication technique that leverages the benefits of both the audio and visual modalities in speech communication. Previous works have demonstrated the usefulness of AV lip biometrics. However, the lack of a sizeable AV database hinders the exploration of deep-learning-based audio-visual lip biometrics. To address this problem, we compile a moderate-size database using existing public databases. Meanwhile, we establish the DeepLip AV lip biometrics system realized with a convolutional neural network (CNN) based video module, a time-delay neural network (TDNN) based audio module, and a multimodal fusion module. Our experiments show that DeepLip outperforms traditional speaker recognition models in context modeling and achieves over 50% relative improvements compared with our best single modality baseline, with an equal error rate of 0.75% and 1.11% on the test datasets, respectively.