 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Contrastive samples via Summarization for Text Classification with limited annotations
Paper and Code
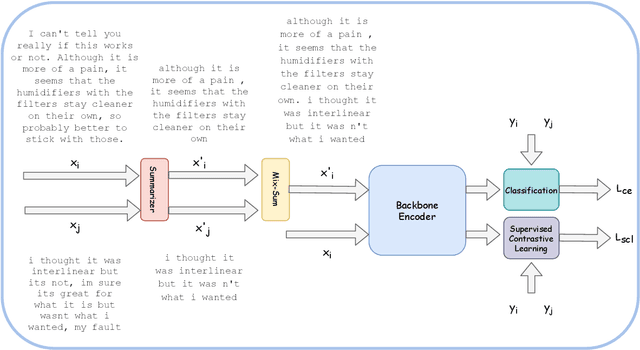
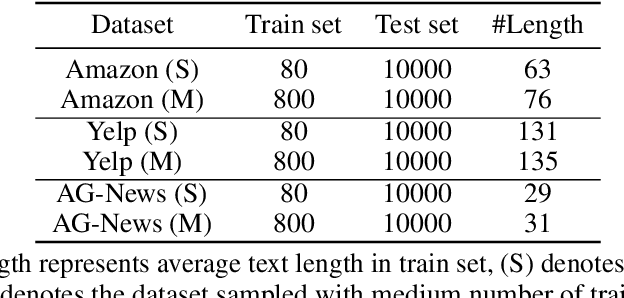
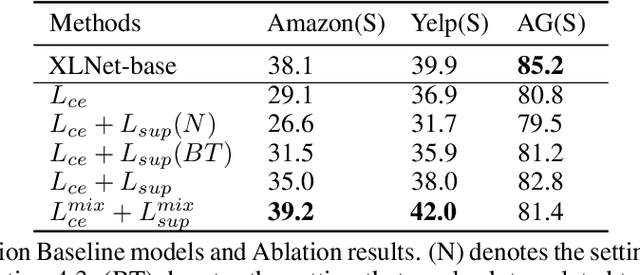
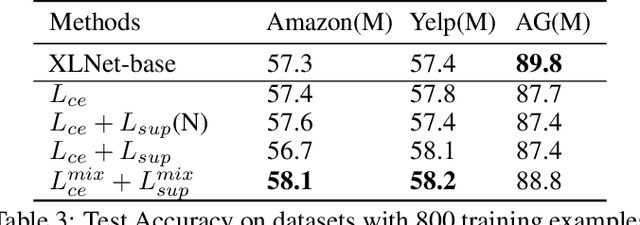
Contrastive Learning has emerged as a powerful representation learning method and facilitates various downstream tasks especially when supervised data is limited. How to construct efficient contrastive samples through data augmentation is key to its success. Unlike vision tasks, the data augmentation method for contrastive learning has not been investigated sufficiently in language tasks. In this paper, we propose a novel approach to constructing contrastive samples for language tasks using text summarization. We use these samples for supervised contrastive learning to gain better text representations which greatly benefit text classification tasks with limited annotations. To further improve the method, we mix up samples from different classes and add an extra regularization, named mix-sum regularization, in addition to the cross-entropy-loss. Experiments on real-world text classification datasets (Amazon-5, Yelp-5, AG News) demonstrate the effectiveness of the proposed contrastive learning framework with summarization-based data augmentation and mix-sum regularization.