 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Representation Drift in Online Continual Learning
Paper and Code
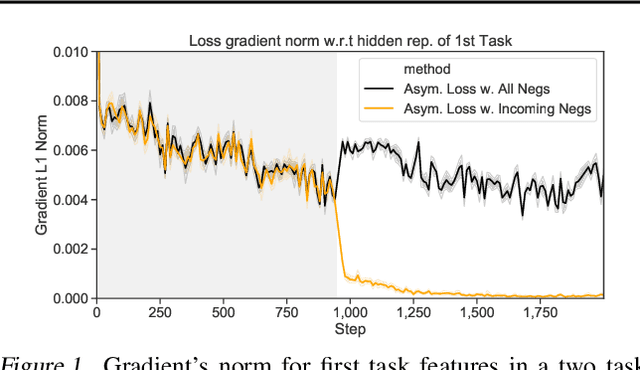
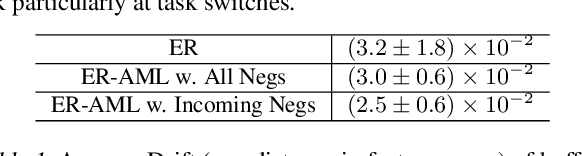
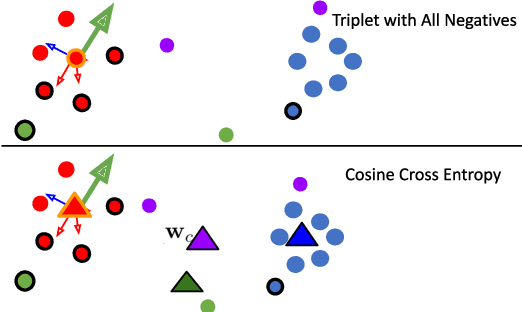
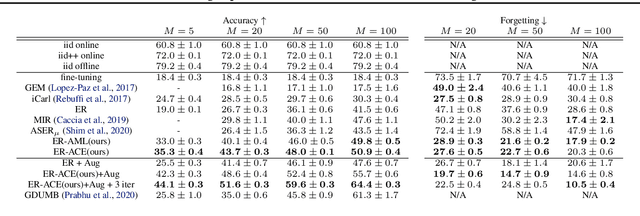
We study the online continual learning paradigm, where agents must learn from a changing distribution with constrained memory and compute. Previous work often tackle catastrophic forgetting by overcoming changes in the space of model parameters. In this work we instead focus on the change in representations of previously observed data due to the introduction of previously unobserved class samples in the incoming data stream. We highlight the issues that arise in the practical setting where new classes must be distinguished between all previous classes. Starting from a popular approach, experience replay, we consider a metric learning based loss function, the triplet loss, which allows us to more explicitly constrain the behavior of representations. We hypothesize and empirically confirm that the selection of negatives used in the triplet loss plays a major role in the representation change, or drift, of previously observed data and can be greatly reduced by appropriate negative selection. Motivated by this we further introduce a simple adjustment to the standard cross entropy loss used in prior experience replay that achieves similar effect. Our approach greatly improves the performance of experience replay and obtains state-of-the-art on several existing benchmarks in online continual learning, while remaining efficient in both memory and compute.