 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Self-Discrepancy via Multiple Co-teaching for Cross-Domain Person Re-Identification
Paper and Code
Apr 06, 2021
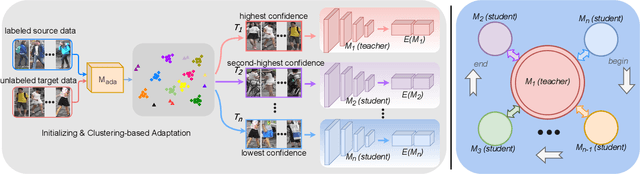
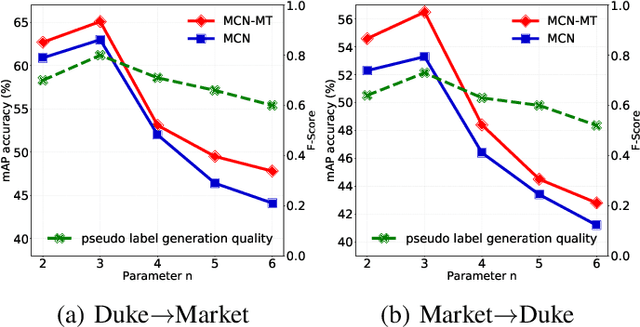

Employing clustering strategy to assign unlabeled target images with pseudo labels has become a trend for person re-identification (re-ID) algorithms in domain adaptation. A potential limitation of these clustering-based methods is that they always tend to introduce noisy labels, which will undoubtedly hamper the performance of our re-ID system. To handle this limitation, an intuitive solution is to utilize collaborative training to purify the pseudo label quality. However, there exists a challenge that the complementarity of two networks, which inevitably share a high similarity, becomes weakened gradually as training process goes on; worse still, these approaches typically ignore to consider the self-discrepancy of intra-class relations. To address this issue, in this letter, we propose a multiple co-teaching framework for domain adaptive person re-ID, opening up a promising direction about self-discrepancy problem under unsupervised condition. On top of that, a mean-teaching mechanism is leveraged to enlarge the difference and discover more complementary features. Comprehensive experiments conducted on several large-scale datasets show that our method achieves competitive performance compared with the state-of-the-arts.