 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Streaming End-to-End Speech Recognition with Trie-Based Deep Biasing and Shallow Fusion
Paper and Code
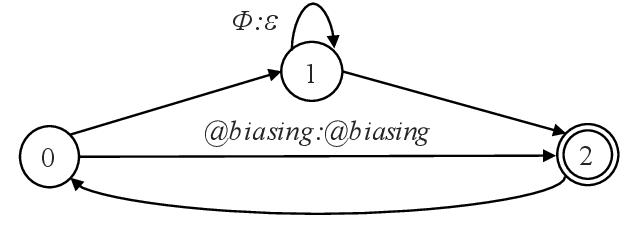
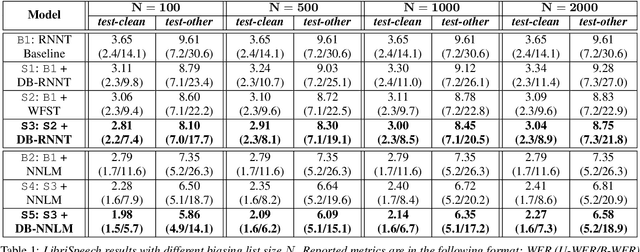
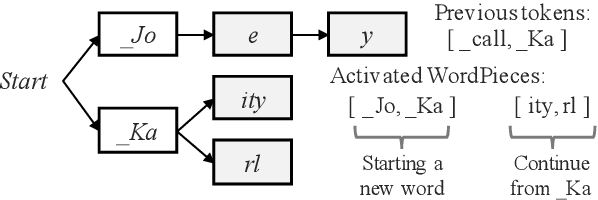
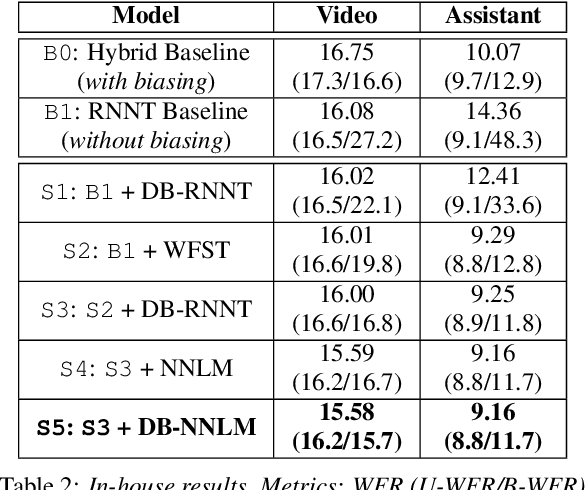
How to leverage dynamic contextual information in end-to-end speech recognition has remained an active research area. Previous solutions to this problem were either designed for specialized use cases that did not generalize well to open-domain scenarios, did not scale to large biasing lists, or underperformed on rare long-tail words. We address these limitations by proposing a novel solution that combines shallow fusion, trie-based deep biasing, and neural network language model contextualization. These techniques result in significant 19.5% relative Word Error Rate improvement over existing contextual biasing approaches and 5.4%-9.3% improvement compared to a strong hybrid baseline on both open-domain and constrained contextualization tasks, where the targets consist of mostly rare long-tail words. Our final system remains lightweight and modular, allowing for quick modification without model re-training.