 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification
Paper and Code
Apr 05, 2021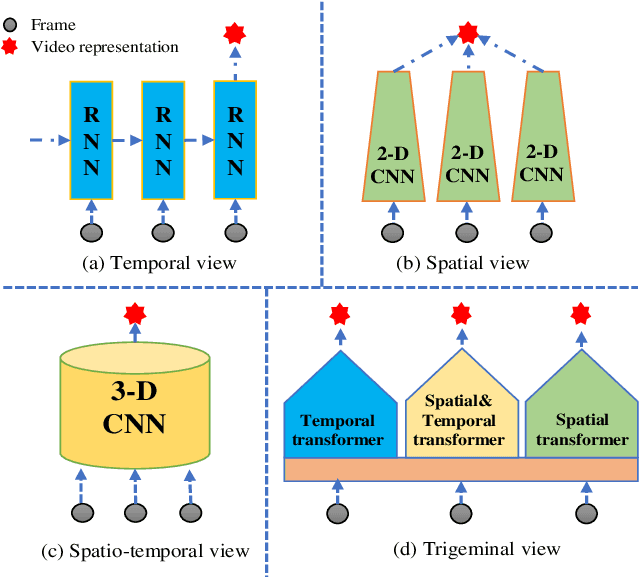
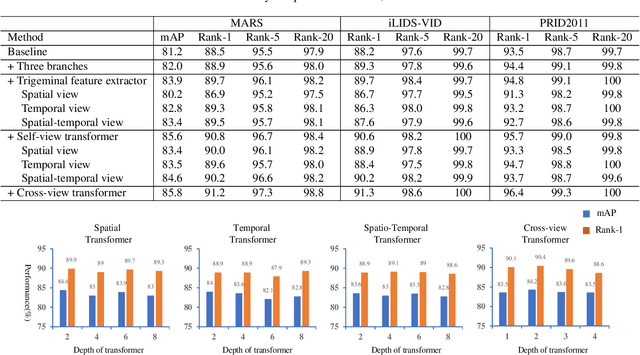
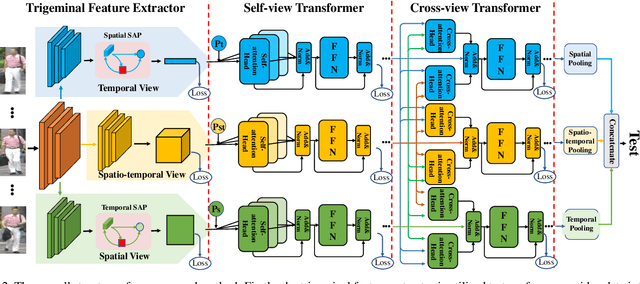
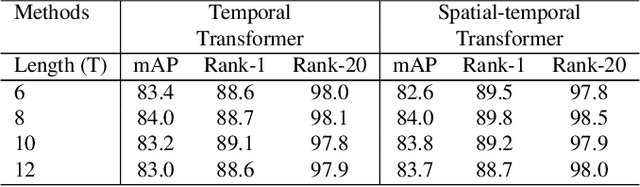
Video-based person re-identification (Re-ID) aims to retrieve video sequences of the same person under non-overlapping cameras. Previous methods usually focus on limited views, such as spatial, temporal or spatial-temporal view, which lack of the observations in different feature domains. To capture richer perceptions and extract more comprehensive video representations, in this paper we propose a novel framework named Trigeminal Transformers (TMT) for video-based person Re-ID. More specifically, we design a trigeminal feature extractor to jointly transform raw video data into spatial, temporal and spatial-temporal domain. Besides, inspired by the great success of vision transformer, we introduce the transformer structure for video-based person Re-ID. In our work, three self-view transformers are proposed to exploit the relationships between local features for information enhancement in spatial, temporal and spatial-temporal domains. Moreover, a cross-view transformer is proposed to aggregate the multi-view features for comprehensive video representations. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches on public Re-ID benchmarks. We will release the code for model reproduction.