 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Transformer for Video-based Person Re-identification
Paper and Code
Mar 30, 2021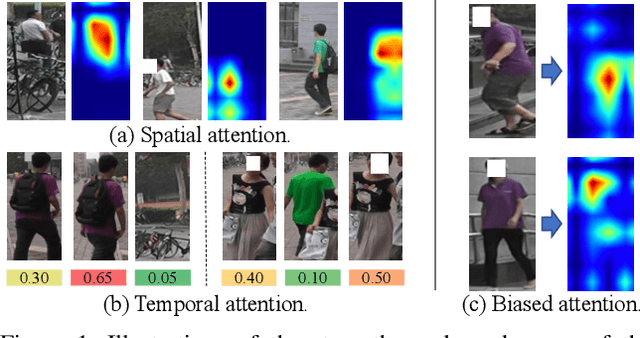
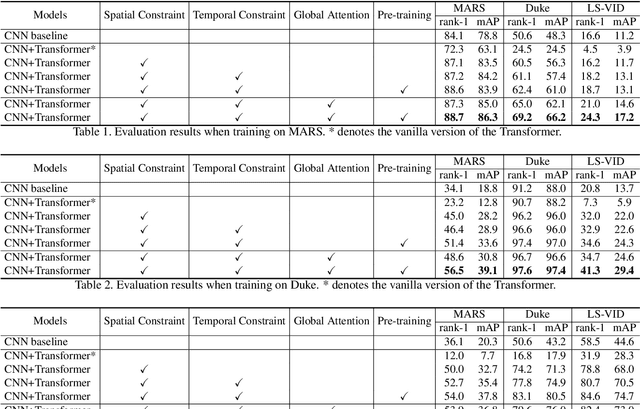
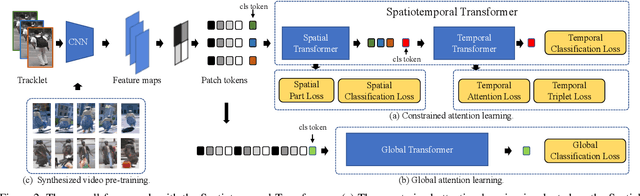
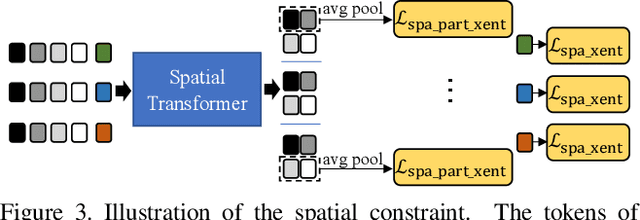
Recently, the Transformer module has been transplanted from natural language processing to computer vision. This paper applies the Transformer to video-based person re-identification, where the key issue is to extract the discriminative information from a tracklet. We show that, despite the strong learning ability, the vanilla Transformer suffers from an increased risk of over-fitting, arguably due to a large number of attention parameters and insufficient training data. To solve this problem, we propose a novel pipeline where the model is pre-trained on a set of synthesized video data and then transferred to the downstream domains with the perception-constrained Spatiotemporal Transformer (STT) module and Global Transformer (GT) module. The derived algorithm achieves significant accuracy gain on three popular video-based person re-identification benchmarks, MARS, DukeMTMC-VideoReID, and LS-VID, especially when the training and testing data are from different domains. More importantly, our research sheds light on the application of the Transformer on highly-structured visual data.