 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond Two Frames: End-to-End Multi-Object Tracking Using Spatial and Temporal Transformers
Paper and Code
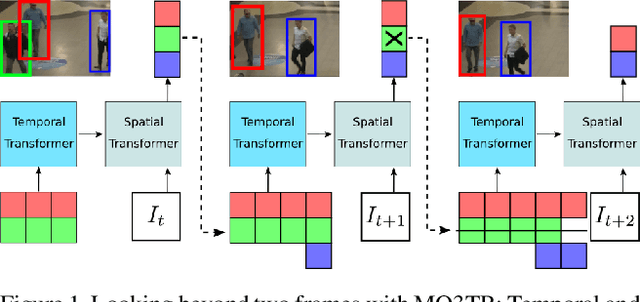
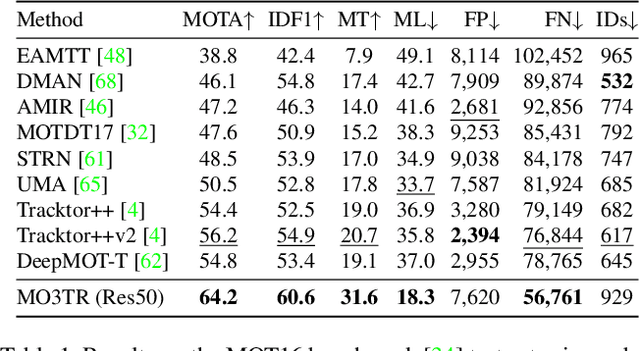
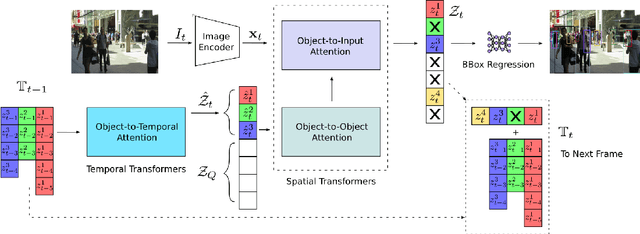
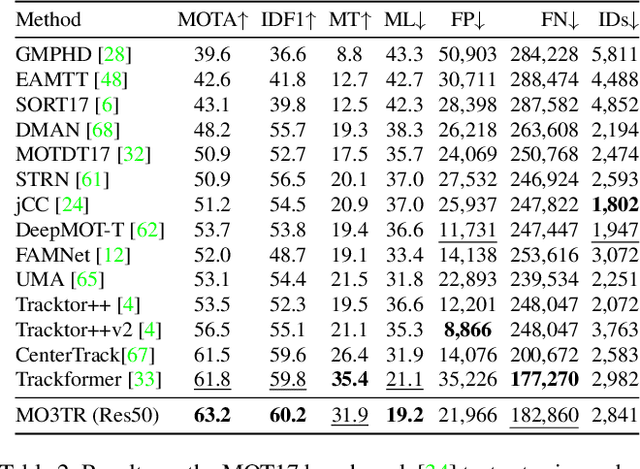
Tracking a time-varying indefinite number of objects in a video sequence over time remains a challenge despite recent advances in the field. Ignoring long-term temporal information, most existing approaches are not able to properly handle multi-object tracking challenges such as occlusion. To address these shortcomings, we present MO3TR: a truly end-to-end Transformer-based online multi-object tracking (MOT) framework that learns to handle occlusions, track initiation and termination without the need for an explicit data association module or any heuristics/post-processing. MO3TR encodes object interactions into long-term temporal embeddings using a combination of spatial and temporal Transformers, and recursively uses the information jointly with the input data to estimate the states of all tracked objects over time. The spatial attention mechanism enables our framework to learn implicit representations between all the objects and the objects to the measurements, while the temporal attention mechanism focuses on specific parts of past information, allowing our approach to resolve occlusions over multiple frames. Our experiments demonstrate the potential of this new approach, reaching new state-of-the-art results on multiple MOT metrics for two popular multi-object tracking benchmarks. Our code will be made publicly available.