 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Improve Robustness of NLP Systems against ASR Errors
Paper and Code

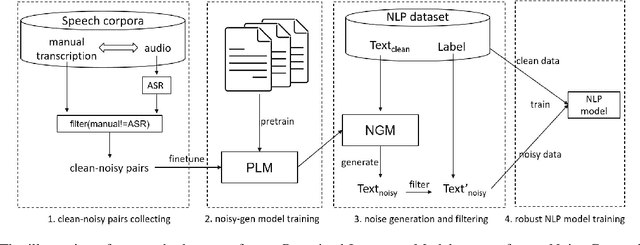


Speech-enabled systems typically first convert audio to text through an automatic speech recognition (ASR) model and then feed the text to downstream natural language processing (NLP) modules. The errors of the ASR system can seriously downgrade the performance of the NLP modules. Therefore, it is essential to make them robust to the ASR errors. Previous work has shown it is effective to employ data augmentation methods to solve this problem by injecting ASR noise during the training process. In this paper, we utilize the prevalent pre-trained language model to generate training samples with ASR-plausible noise. Compare to the previous methods, our approach generates ASR noise that better fits the real-world error distribution. Experimental results on spoken language translation(SLT) and spoken language understanding (SLU) show that our approach effectively improves the system robustness against the ASR errors and achieves state-of-the-art results on both tasks.