 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Off-Policy TD Learning: Finite-Time Analysis with Near-Optimal Sample Complexity and Communication Complexity
Paper and Code
Mar 24, 2021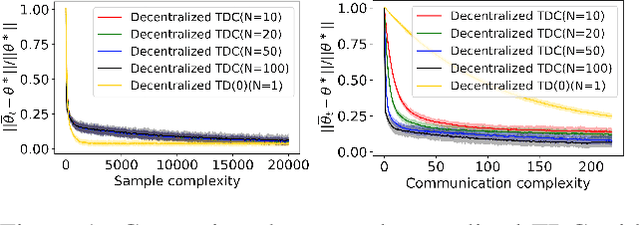
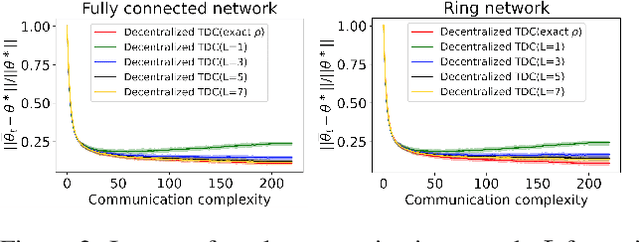
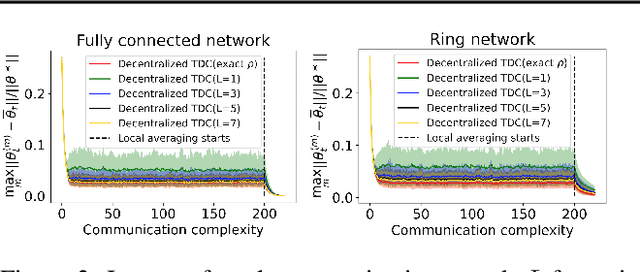
The finite-time convergence of off-policy TD learning has been comprehensively studied recently. However, such a type of convergence has not been well established for off-policy TD learning in the multi-agent setting, which covers broader applications and is fundamentally more challenging. This work develops two decentralized TD with correction (TDC) algorithms for multi-agent off-policy TD learning under Markovian sampling. In particular, our algorithms preserve full privacy of the actions, policies and rewards of the agents, and adopt mini-batch sampling to reduce the sampling variance and communication frequency. Under Markovian sampling and linear function approximation, we proved that the finite-time sample complexity of both algorithms for achieving an $\epsilon$-accurate solution is in the order of $\mathcal{O}(\epsilon^{-1}\ln \epsilon^{-1})$, matching the near-optimal sample complexity of centralized TD(0) and TDC. Importantly, the communication complexity of our algorithms is in the order of $\mathcal{O}(\ln \epsilon^{-1})$, which is significantly lower than the communication complexity $\mathcal{O}(\epsilon^{-1}\ln \epsilon^{-1})$ of the existing decentralized TD(0). Experiments corroborate our theoretical findings.