 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacing Rewards with Examples: Example-Based Policy Search via Recursive Classification
Paper and Code
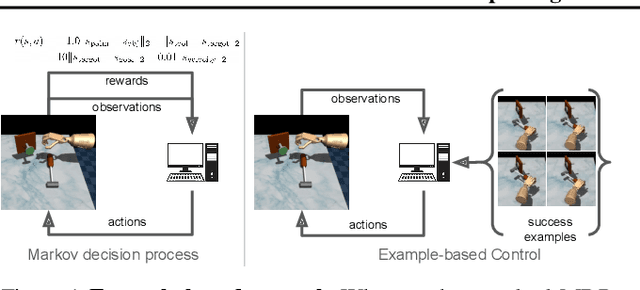

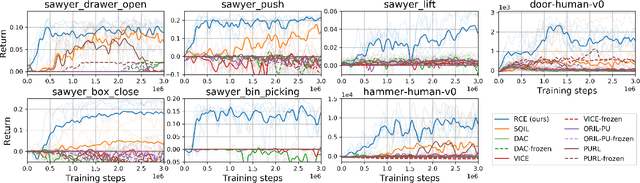

In the standard Markov decision process formalism, users specify tasks by writing down a reward function. However, in many scenarios, the user is unable to describe the task in words or numbers, but can readily provide examples of what the world would look like if the task were solved. Motivated by this observation, we derive a control algorithm from first principles that aims to visit states that have a high probability of leading to successful outcomes, given only examples of successful outcome states. Prior work has approached similar problem settings in a two-stage process, first learning an auxiliary reward function and then optimizing this reward function using another reinforcement learning algorithm. In contrast, we derive a method based on recursive classification that eschews auxiliary reward functions and instead directly learns a value function from transitions and successful outcomes. Our method therefore requires fewer hyperparameters to tune and lines of code to debug. We show that our method satisfies a new data-driven Bellman equation, where examples take the place of the typical reward function term. Experiments show that our approach outperforms prior methods that learn explicit reward functions.