 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Contrast for Unsupervised Person Re-Identification
Paper and Code
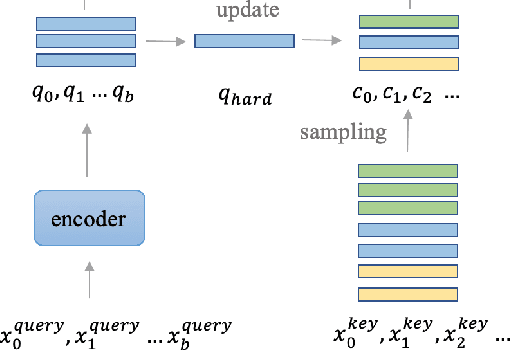

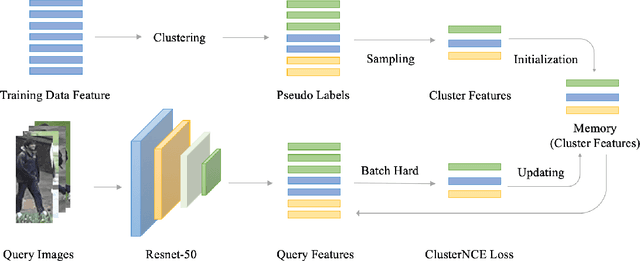
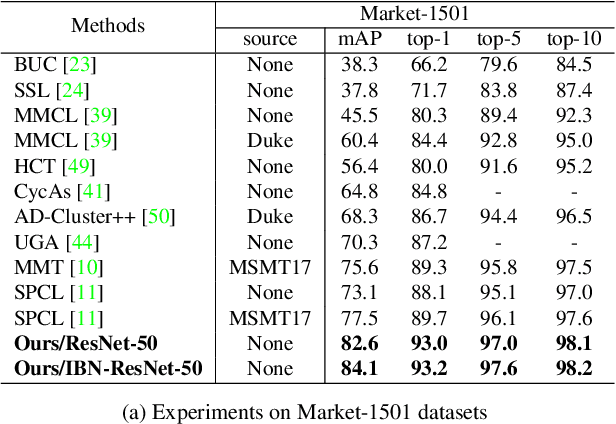
Unsupervised person re-identification (re-ID) attracts increasing attention due to its practical applications in industry. State-of-the-art unsupervised re-ID methods train the neural networks using a memory-based non-parametric softmax loss. They store the pre-computed instance feature vectors inside the memory, assign pseudo labels to them us-ing clustering algorithm, and compare the query instances to the cluster using a form of contrastive loss. During training, the instance feature vectors are updated. How-ever, due to the varying cluster size, the updating progress for each cluster is inconsistent. To solve this problem, we present Cluster Contrast which stores feature vectors and computes contrast loss in the cluster level. We demonstrate that the inconsistency problem for cluster feature representation can be solved by the cluster-level memory dictionary.By straightforwardly applying Cluster Contrast to a standard unsupervised re-ID pipeline, it achieves considerable improvements of 9.5%, 7.5%, 6.6% compared to state-of-the-art purely unsupervised re-ID methods and 5.1%, 4.0%,6.5% mAP compared to the state-of-the-art unsupervised domain adaptation re-ID methods on the Market, Duke, andMSMT17 datasets.Our source code is available at https://github.com/alibaba/cluster-contrast.