 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Behavior Value Estimation
Paper and Code

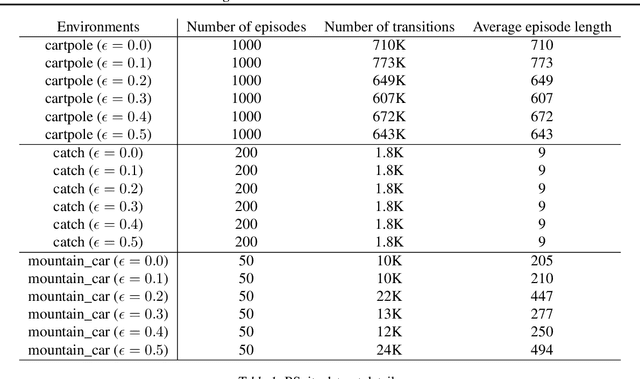
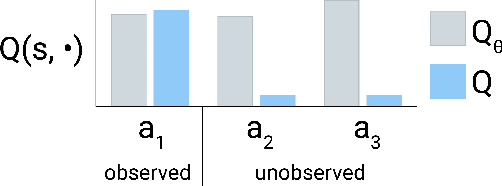
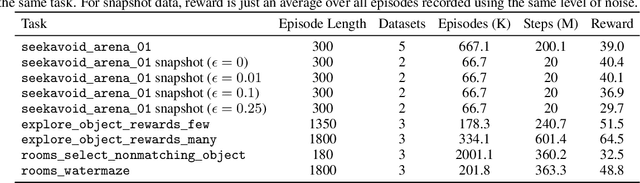
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.