 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary Proposal Network for Two-Stage Natural Language Video Localization
Paper and Code
Mar 15, 2021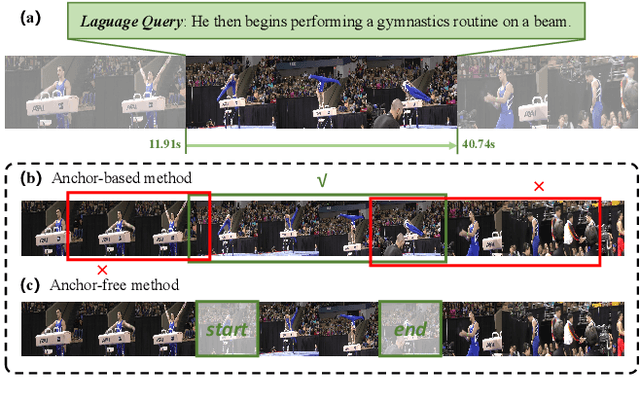
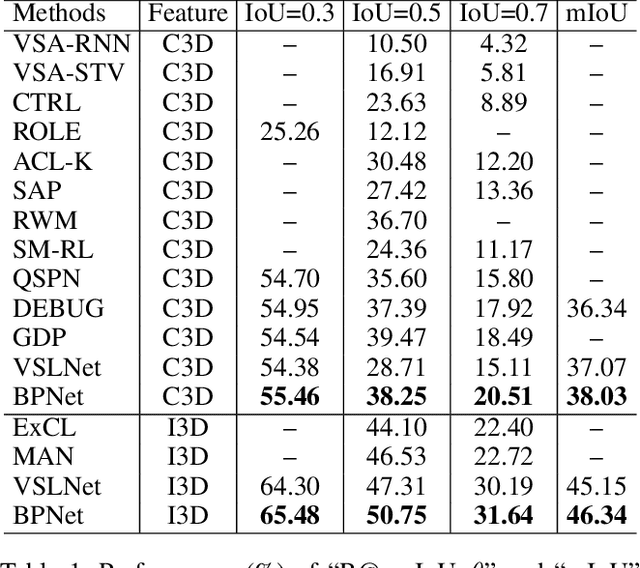
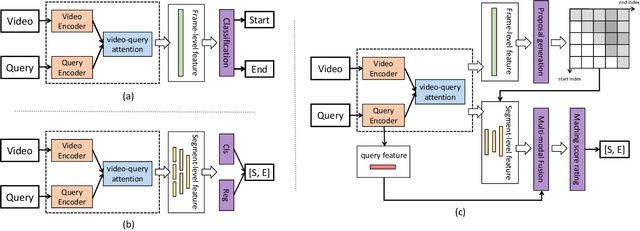
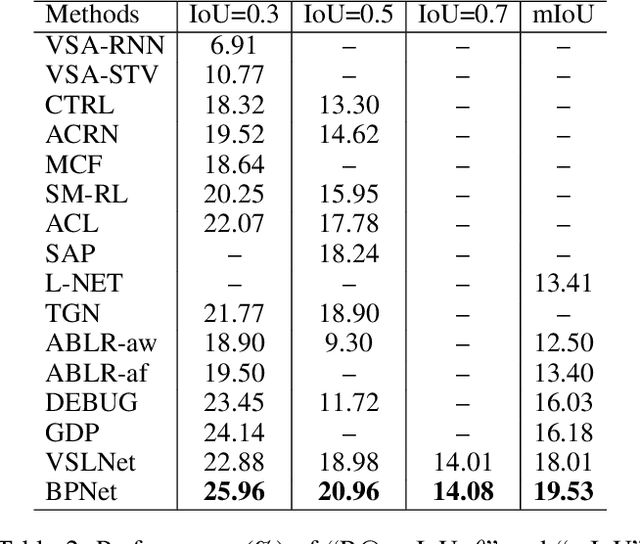
We aim to address the problem of Natural Language Video Localization (NLVL)-localizing the video segment corresponding to a natural language description in a long and untrimmed video. State-of-the-art NLVL methods are almost in one-stage fashion, which can be typically grouped into two categories: 1) anchor-based approach: it first pre-defines a series of video segment candidates (e.g., by sliding window), and then does classification for each candidate; 2) anchor-free approach: it directly predicts the probabilities for each video frame as a boundary or intermediate frame inside the positive segment. However, both kinds of one-stage approaches have inherent drawbacks: the anchor-based approach is susceptible to the heuristic rules, further limiting the capability of handling videos with variant length. While the anchor-free approach fails to exploit the segment-level interaction thus achieving inferior results. In this paper, we propose a novel Boundary Proposal Network (BPNet), a universal two-stage framework that gets rid of the issues mentioned above. Specifically, in the first stage, BPNet utilizes an anchor-free model to generate a group of high-quality candidate video segments with their boundaries. In the second stage, a visual-language fusion layer is proposed to jointly model the multi-modal interaction between the candidate and the language query, followed by a matching score rating layer that outputs the alignment score for each candidate. We evaluate our BPNet on three challenging NLVL benchmarks (i.e., Charades-STA, TACoS and ActivityNet-Captions). Extensive experiments and ablative studies on these datasets demonstrate that the BPNet outperforms the state-of-the-art methods.