 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human Rewards by Inferring Their Latent Intelligence Levels in Multi-Agent Games: A Theory-of-Mind Approach with Application to Driving Data
Paper and Code
Mar 07, 2021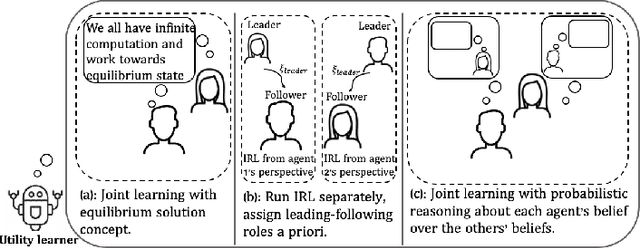
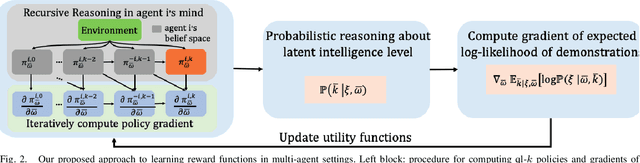
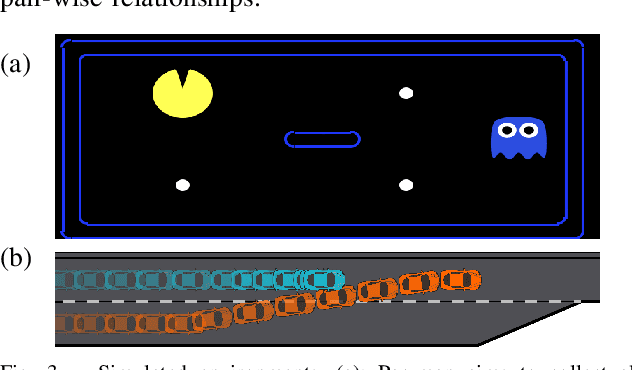
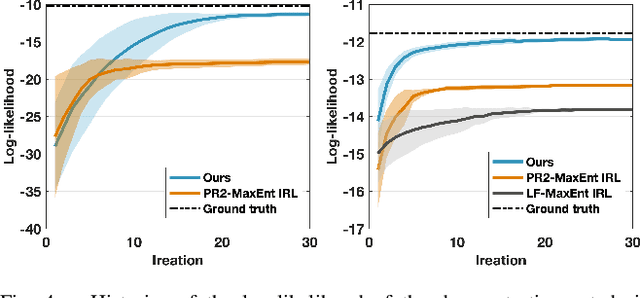
Reward function, as an incentive representation that recognizes humans' agency and rationalizes humans' actions, is particularly appealing for modeling human behavior in human-robot interaction. Inverse Reinforcement Learning is an effective way to retrieve reward functions from demonstrations. However, it has always been challenging when applying it to multi-agent settings since the mutual influence between agents has to be appropriately modeled. To tackle this challenge, previous work either exploits equilibrium solution concepts by assuming humans as perfectly rational optimizers with unbounded intelligence or pre-assigns humans' interaction strategies a priori. In this work, we advocate that humans are bounded rational and have different intelligence levels when reasoning about others' decision-making process, and such an inherent and latent characteristic should be accounted for in reward learning algorithms. Hence, we exploit such insights from Theory-of-Mind and propose a new multi-agent Inverse Reinforcement Learning framework that reasons about humans' latent intelligence levels during learning. We validate our approach in both zero-sum and general-sum games with synthetic agents and illustrate a practical application to learning human drivers' reward functions from real driving data. We compare our approach with two baseline algorithms. The results show that by reasoning about humans' latent intelligence levels, the proposed approach has more flexibility and capability to retrieve reward functions that explain humans' driving behaviors better.