 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple But Effective Approach to n-shot Task-Oriented Dialogue Augmentation
Paper and Code
Mar 02, 2021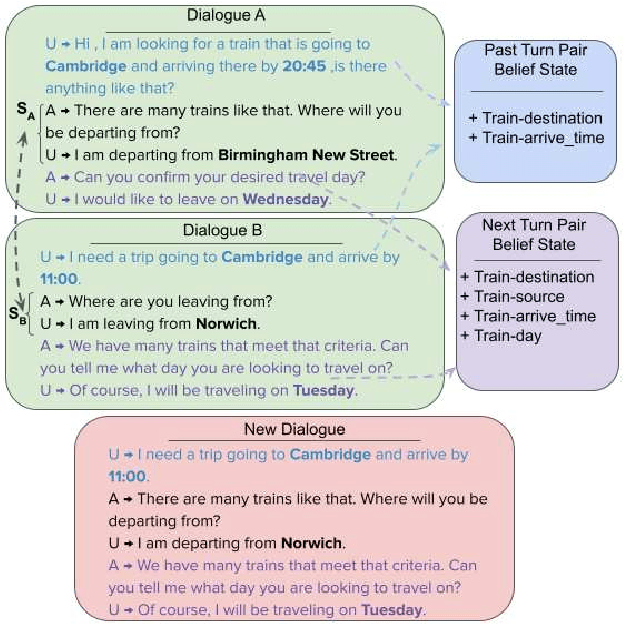
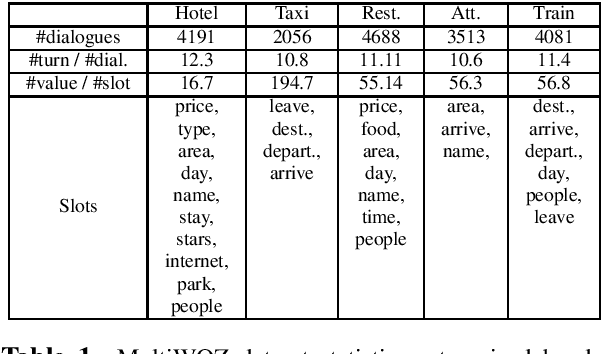

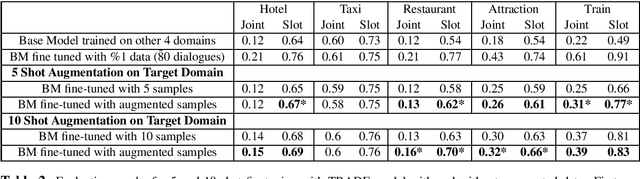
The collection and annotation of task-oriented conversational data is a costly and time-consuming manner. Many augmentation techniques have been proposed to improve the performance of state-of-the-art (SOTA) systems in new domains that lack the necessary amount of data for training. However, these augmentation techniques (e.g. paraphrasing) also require some mediocre amount of data since they use learning-based approaches. This makes using SOTA systems in emerging low-resource domains infeasible. We, to tackle this problem, introduce a framework, that creates synthetic task-oriented dialogues in a fully automatic manner, which operates with input sizes of as small as a few dialogues. Our framework uses the simple idea that each turn-pair in a task-oriented dialogue has a certain function and exploits this idea to mix them creating new dialogues. We evaluate our framework within a low-resource setting by integrating it with a SOTA model TRADE in the dialogue state tracking task and observe significant improvements in the fine-tuning scenarios in several domains. We conclude that this end-to-end dialogue augmentation framework can be a crucial tool for natural language understanding performance in emerging task-oriented dialogue domains.